Let’s use Python to explore the concepts of conditional probability. We’ll need libraries like numpy for numerical operations and random sampling, and potentially pandas for handling data.
import numpy as np
import pandas as pd
import randomSimulating Conditional Events: Drawing Cards¶
Let’s simulate drawing two cards from a standard 52-card deck without replacement and verify the conditional probability . We expect this to be .
Explanation
Conditional Probability:
Imagine you’ve already drawn one card, and it’s a King. Since we’re drawing without replacement, that King is now out of the deck.
Remaining Cards: After drawing one King, there are now cards left in the deck.
Remaining Kings: Since one King has been removed, there are now Kings remaining.
Therefore, the probability that the second card you draw is a King, given that the first card was a King, is the number of remaining Kings divided by the total number of remaining cards, which is .
We can also estimate the overall probability . By symmetry or using the Law of Total Probability, this should be .
Explanation
Overall Probability:
Now, let’s think about the probability of the second card being a King without knowing anything about the first card. There are a couple of ways to see why this is :
Symmetry: Consider each of the 52 cards in the deck. Each card has an equal chance of being in the second position of the draw. Since there are 4 Kings in the deck, the probability that the card in the second position is a King must be the same as the probability that the card in the first position is a King, which is .
Law of Total Probability (Implicitly): We can think about the two possibilities for the first card:
Case 1: The first card is a King. The probability of this is . In this case, the probability of the second card being a King is .
Case 2: The first card is not a King. The probability of this is . In this case, there are still 4 Kings left in the remaining 51 cards, so the probability of the second card being a King is .
Using the Law of Total Probability:
So, both our intuition and a more formal application of probability rules confirm these results! Now, are you ready to simulate this?
# Represent the deck
ranks = ['2', '3', '4', '5', '6', '7', '8', '9', 'T', 'J', 'Q', 'K', 'A']
suits = ['H', 'D', 'C', 'S'] # Hearts, Diamonds, Clubs, Spades
deck = [rank + suit for rank in ranks for suit in suits]
kings = {'KH', 'KD', 'KC', 'KS'}# Simulation parameters
num_simulations = 100000# Counters
count_first_king = 0
count_second_king = 0
count_both_king = 0
count_second_king_given_first_king = 0# Run simulations
for _ in range(num_simulations):
# Shuffle the deck implicitly by drawing random samples
drawn_cards = random.sample(deck, 2)
card1 = drawn_cards[0]
card2 = drawn_cards[1]
# Check conditions
is_first_king = card1 in kings
is_second_king = card2 in kings
if is_first_king:
count_first_king += 1
if is_second_king:
count_second_king_given_first_king += 1
if is_second_king:
count_second_king += 1
if is_first_king and is_second_king:
count_both_king += 1# Calculate probabilities from simulation
prob_first_king_sim = count_first_king / num_simulations
prob_second_king_sim = count_second_king / num_simulations
prob_both_king_sim = count_both_king / num_simulations# Calculate conditional probability P(B|A) = P(A and B) / P(A)
# We can estimate this directly from the counts:
if count_first_king > 0:
prob_second_given_first_sim = count_second_king_given_first_king / count_first_king
else:
prob_second_given_first_sim = 0# Theoretical values
prob_first_king_theory = 4/52
prob_second_king_theory = 4/52 # By symmetry
prob_both_king_theory = (4/52) * (3/51)
prob_second_given_first_theory = 3/51# Print results
print(f"--- Theoretical Probabilities ---")
print(f"P(1st is King): {prob_first_king_theory:.6f} ({4}/{52})")
print(f"P(2nd is King): {prob_second_king_theory:.6f} ({4}/{52})")
print(f"P(Both Kings): {prob_both_king_theory:.6f}")
print(f"P(2nd is King | 1st is King): {prob_second_given_first_theory:.6f} ({3}/{51})")
print("\n")
print(f"--- Simulation Results ({num_simulations} runs) ---")
print(f"Estimated P(1st is King): {prob_first_king_sim:.6f}")
print(f"Estimated P(2nd is King): {prob_second_king_sim:.6f}")
print(f"Estimated P(Both Kings): {prob_both_king_sim:.6f}")
print(f"Estimated P(2nd is King | 1st is King): {prob_second_given_first_sim:.6f}")--- Theoretical Probabilities ---
P(1st is King): 0.076923 (4/52)
P(2nd is King): 0.076923 (4/52)
P(Both Kings): 0.004525
P(2nd is King | 1st is King): 0.058824 (3/51)
--- Simulation Results (100000 runs) ---
Estimated P(1st is King): 0.077360
Estimated P(2nd is King): 0.076210
Estimated P(Both Kings): 0.004760
Estimated P(2nd is King | 1st is King): 0.061531
The simulation results should be very close to the theoretical values, demonstrating how simulation can approximate probabilistic calculations. The larger num_simulations, the closer the estimates will typically be.
Calculating Conditional Probabilities from Data¶
Imagine we have data about website visitors, including whether they made a purchase and whether they visited a specific product page first. We can use Pandas to calculate conditional probabilities from this data.
Sample Data¶
A DataFrame is created with data on website visitors, including whether they visited a specific product page and whether they made a purchase.
import pandas as pd
# Create sample data
data = {
'visited_product_page': [True, False, True, True, False, False, True, True, False, True],
'made_purchase': [True, False, False, True, False, True, False, True, False, False]
}
df = pd.DataFrame(data)
print("Sample Visitor Data:")
display(df)
print("\n")Sample Visitor Data:
Approach 1: Calculated Conditional Probability¶
First calculate basic probabilities:
Basic Probabilities: The total number of visitors, visitors who visited the product page, visitors who made a purchase, and visitors who both visited the product page and made a purchase are calculated. These are used to compute the basic probabilities:
# Calculate basic probabilities
n_total = len(df)
n_visited_page = df['visited_product_page'].sum()
n_purchased = df['made_purchase'].sum()
n_visited_and_purchased = len(df[(df['visited_product_page'] == True) & (df['made_purchase'] == True)])
P_visited = n_visited_page / n_total
P_purchased = n_purchased / n_total
P_visited_and_purchased = n_visited_and_purchased / n_total
print(f"P(Visited Page) = {P_visited:.2f}")
print(f"P(Purchased) = {P_purchased:.2f}")
print(f"P(Visited and Purchased) = {P_visited_and_purchased:.2f}")
print("\n")P(Visited Page) = 0.60
P(Purchased) = 0.40
P(Visited and Purchased) = 0.30
Next calculate conditional probabilities:
Definition: This approach uses the fundamental rules of probability to derive conditional probabilities.
Calculations:
: Calculated using the formula , where is “Purchased” and is “Visited Page”.
: Similarly calculated using the same probability rule.
Advantage: This method is useful when you already have the probabilities and and want to use them to find the conditional probability. It’s also helpful for understanding the theoretical underpinnings of conditional probability.
# Calculate Conditional Probability: P(Purchase | Visited Page)
if P_visited > 0:
P_purchased_given_visited = P_visited_and_purchased / P_visited
print(f"Calculated P(Purchased | Visited Page) = {P_purchased_given_visited:.2f}")
else:
print("Cannot calculate P(Purchased | Visited Page) as P(Visited Page) is 0.")
# Calculate Conditional Probability: P(Visited Page | Purchased)
if P_purchased > 0:
P_visited_given_purchased = P_visited_and_purchased / P_purchased
print(f"Calculated P(Visited Page | Purchased) = {P_visited_given_purchased:.2f}")
else:
print("Cannot calculate P(Visited Page | Purchased) as P(Purchased) is 0.")Calculated P(Purchased | Visited Page) = 0.50
Calculated P(Visited Page | Purchased) = 0.75
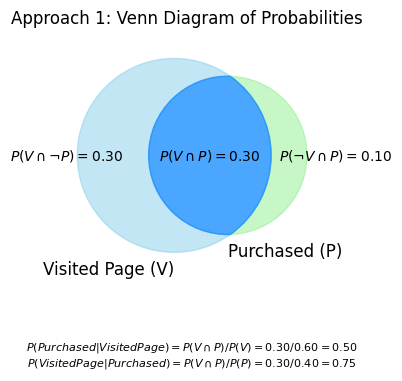
This Venn diagram visually clarifies how different probabilities are related:
Specific Outcomes: The values inside each distinct segment of the diagram show the probability of that particular, unique scenario occurring. For example:
represents the probability of a visitor ‘Visiting the Page but Not Purchasing’.
represents the probability of a visitor ‘Visiting the Page AND Purchasing’.
Total Event Probabilities: The total probability for an entire event (like ‘Visited Page’, denoted as ) is found by summing the probabilities of all the individual segments that make up that event.
For instance, .
Components for Conditional Probability: This total probability (e.g., ), along with the probability of the intersection (e.g., ), are the essential values used in the formula for conditional probability.
For example, .
Visualizing the Sample Space: The diagram effectively helps to see how the entire circle of the conditioning event (e.g., the ‘Visited Page’ circle, representing the total ) becomes the new, reduced sample space when calculating a conditional probability.
Approach 2: Direct Conditional Probability¶
Definition: This approach involves filtering the data to directly calculate the conditional probabilities from the relevant subset of data.
Calculations:
: The DataFrame is filtered to include only visitors who visited the product page. The number of these visitors who made a purchase is then divided by the total number of visitors who visited the page.
: The DataFrame is filtered to include only visitors who made a purchase. The number of these visitors who visited the product page is then divided by the total number of visitors who made a purchase.
Advantage: This method is straightforward and intuitive because it directly uses the relevant subset of data.
# Direct calculation from counts: P(Purchase | Visited Page)
df_visited = df[df['visited_product_page'] == True]
n_purchased_in_visited = df_visited['made_purchase'].sum()
n_visited = len(df_visited)
if n_visited > 0:
P_purchased_given_visited_direct = n_purchased_in_visited / n_visited
print(f"Direct P(Purchased | Visited Page) = {P_purchased_given_visited_direct:.2f} ({n_purchased_in_visited}/{n_visited})")
else:
print("Cannot calculate P(Purchased | Visited Page) directly as no one visited the page.")
# Direct calculation from counts: P(Visited Page | Purchased)
df_purchased = df[df['made_purchase'] == True]
n_visited_in_purchased = df_purchased['visited_product_page'].sum()
n_purchased_total = len(df_purchased)
if n_purchased_total > 0:
P_visited_given_purchased_direct = n_visited_in_purchased / n_purchased_total
print(f"Direct P(Visited Page | Purchased) = {P_visited_given_purchased_direct:.2f} ({n_visited_in_purchased}/{n_purchased_total})")
else:
print("Cannot calculate P(Visited Page | Purchased) directly as no one made a purchase.")Direct P(Purchased | Visited Page) = 0.50 (3/6)
Direct P(Visited Page | Purchased) = 0.75 (3/4)
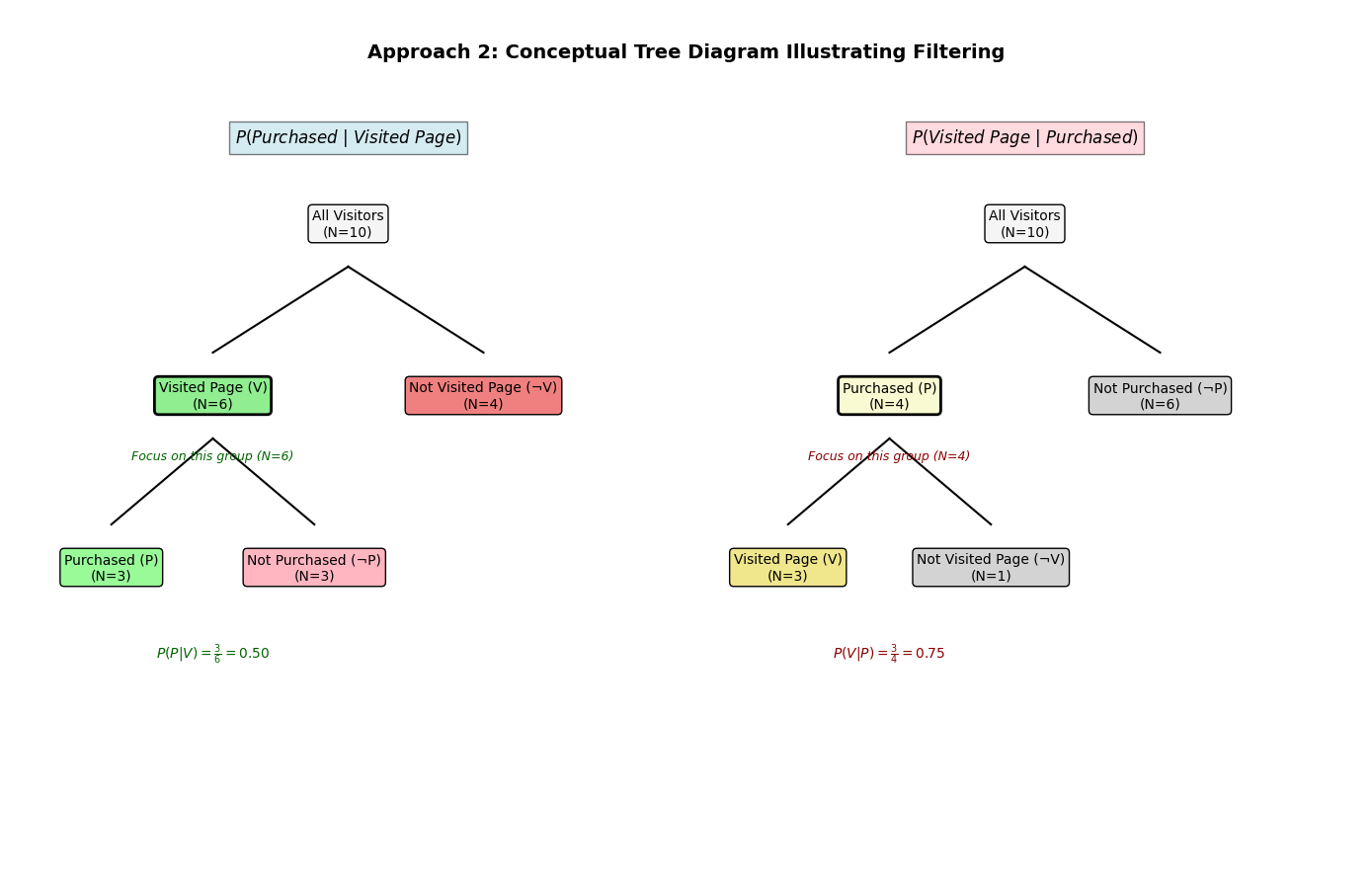
This tree diagram illustrates the direct approach to conditional probability by visually segmenting the visitor population based on a sequence of events or conditions. To find , for instance, you first follow the branch representing ‘Visited Page’, effectively filtering the data, and then observe the proportion of those visitors who subsequently ‘Made Purchase’. The diagram clearly shows how the initial condition narrows the focus to a specific subgroup before the probability of the second event is determined within that subgroup.
Summary¶
Calculated Approach: Uses probability rules to derive conditional probabilities from known probabilities.
Direct Approach: Filters the data to the condition and performs the calculation on the filtered data.
Both approaches should yield the same results if done correctly, and the choice between them can depend on the context and what data or probabilities you already have at hand.
This example shows how to compute conditional probabilities directly from observed data, a common task in data analysis. tells us the likelihood of a purchase among those who visited the specific page, while tells us the likelihood that someone who did purchase had previously visited that page. These can be very different values!
Applying the Law of Total Probability¶
Let’s use the Law of Total Probability with a manufacturing example. Suppose a factory has two machines, M1 and M2, producing widgets.
Machine M1 produces 60% of the widgets ().
Machine M2 produces 40% of the widgets ().
2% of widgets from M1 are defective ().
5% of widgets from M2 are defective ().
What is the overall probability that a randomly selected widget is defective ()?
The events M1 (widget produced by M1) and M2 (widget produced by M2) form a partition of the sample space (all widgets). Using the Law of Total Probability:
# Define probabilities
P_M1 = 0.60
P_M2 = 0.40
P_D_given_M1 = 0.02
P_D_given_M2 = 0.05# Apply Law of Total Probability
P_D = (P_D_given_M1 * P_M1) + (P_D_given_M2 * P_M2)print(f"P(Defective | M1) = {P_D_given_M1}")
print(f"P(M1) = {P_M1}")
print(f"P(Defective | M2) = {P_D_given_M2}")
print(f"P(M2) = {P_M2}")
print("\n")
print(f"Overall Probability of a Defective Widget P(D) = ({P_D_given_M1} * {P_M1}) + ({P_D_given_M2} * {P_M2}) = {P_D:.4f}")P(Defective | M1) = 0.02
P(M1) = 0.6
P(Defective | M2) = 0.05
P(M2) = 0.4
Overall Probability of a Defective Widget P(D) = (0.02 * 0.6) + (0.05 * 0.4) = 0.0320
So, the overall probability of finding a defective widget is 3.2%. This weighted average reflects that while M2 produces more defective items proportionatly, M1 produces more items overall.
We could also simulate this:
num_widgets_sim = 100000
defective_count = 0for _ in range(num_widgets_sim):
# Decide which machine produced the widget
if random.random() < P_M1: # Simulates P(M1)
# Widget from M1
# Check if it's defective
if random.random() < P_D_given_M1: # Simulates P(D|M1)
defective_count += 1
else:
# Widget from M2
# Check if it's defective
if random.random() < P_D_given_M2: # Simulates P(D|M2)
defective_count += 1# Estimate P(D) from simulation
P_D_sim = defective_count / num_widgets_simprint(f"\n--- Simulation Results ({num_widgets_sim} widgets) ---")
print(f"Estimated overall P(Defective): {P_D_sim:.4f}")
--- Simulation Results (100000 widgets) ---
Estimated overall P(Defective): 0.0322
Again, the simulation provides an estimate very close to the calculated value.
This chapter introduced conditional probability, the multiplication rule, the law of total probability, and tree diagrams. These concepts are crucial for reasoning under uncertainty and form the basis for more advanced topics like Bayes’ Theorem, which we will explore in the next chapter. The hands-on examples demonstrated how to calculate and simulate these probabilities using Python.
Okay, here is the entire “Exercises” section with the questions followed by their respective dropdown explanations: