Introduction¶
In the previous chapters, we explored individual random variables and their distributions, as well as how multiple variables interact. Now, we venture into the fascinating realm of limit theorems. These theorems describe the long-term behavior of sequences of random variables, forming the theoretical bedrock for many statistical methods and simulations.
The first major limit theorem we’ll explore is the Law of Large Numbers (LLN). Intuitively, the LLN tells us that if we repeat an experiment independently many times, the average of the outcomes will tend to get closer and closer to the theoretical expected value of the experiment. This aligns with our everyday understanding – flip a fair coin enough times, and the proportion of heads will likely be very close to 50%. The LLN provides the mathematical justification for this intuition and is fundamental to why simulation methods, like Monte Carlo, work.
In this chapter, we will:
Introduce Chebyshev’s Inequality, a tool that provides a bound on how likely a random variable is to deviate far from its mean.
Define and explain the Weak Law of Large Numbers (WLLN), focusing on convergence in probability.
Discuss the conceptual difference with the Strong Law of Large Numbers (SLLN).
Illustrate the practical implications, particularly how the LLN justifies Monte Carlo simulations.
Use Python simulations to visualize the convergence described by the LLN.
Let’s begin by looking at an inequality that helps us quantify deviations from the mean.
Chebyshev’s Inequality¶
Chebyshev’s Inequality provides a way to estimate the probability that a random variable takes a value far from its mean, using only its mean () and variance (). It’s powerful because it applies regardless of the specific distribution of the random variable, as long as the mean and variance are finite.
Theorem (Chebyshev’s Inequality): Let be a random variable with finite mean and finite variance . Then, for any real number :
Alternatively, letting for some , the inequality can be written as:
This second form states that the probability of being or more standard deviations away from its mean is at most .
For , the probability of being 2 or more standard deviations away is at most .
For , the probability of being 3 or more standard deviations away is at most .
Interpretation: Chebyshev’s inequality gives us a guaranteed upper bound on the probability of large deviations. This bound is often quite loose (i.e., the actual probability might be much smaller), especially if we know more about the distribution (like if it’s Normal). However, its universality makes it very useful in theoretical contexts.
Example: Suppose the average daily return of a stock () is 0.05% and the standard deviation () is 1%. What is the maximum probability that the return on a given day is outside the range [-1.95%, 2.05%]? This range corresponds to being away from the mean, where , so . Using Chebyshev’s inequality with : . So, there’s at most a 25% chance that the daily return falls outside the [-1.95%, 2.05%] range, regardless of the specific distribution shape (as long as mean and variance are as stated).
Hands-on: Illustrating Chebyshev’s Bound¶
Let’s consider a Binomial random variable, say . We know . And , so .
Let’s check the probability of being standard deviations away from the mean. That is, . This means we want .
Chebyshev’s inequality states: .
Let’s calculate the actual probability using scipy.stats.
import numpy as np
from scipy.stats import binom
import matplotlib.pyplot as plt
# Configure plot style
plt.style.use('seaborn-v0_8-whitegrid')
# Parameters
n = 100
p = 0.5
mu = n * p
sigma = np.sqrt(n * p * (1 - p))
k = 2
epsilon = k * sigma
# Calculate the actual probability P(|X - mu| >= k*sigma)
# This is P(X <= mu - k*sigma) + P(X >= mu + k*sigma)
# Since Binomial is discrete, we need P(X <= floor(mu - k*sigma)) + P(X >= ceil(mu + k*sigma))
lower_bound = np.floor(mu - epsilon)
upper_bound = np.ceil(mu + epsilon)
prob_lower = binom.cdf(k=lower_bound, n=n, p=p)
prob_upper = 1.0 - binom.cdf(k=upper_bound - 1, n=n, p=p) # P(X >= upper_bound) = 1 - P(X < upper_bound) = 1 - P(X <= upper_bound - 1)
actual_prob = prob_lower + prob_upper
# Chebyshev bound
chebyshev_bound = 1 / (k**2)
print(f"Distribution: Binomial(n={n}, p={p})")
print(f"Mean (mu): {mu}, Standard Deviation (sigma): {sigma:.2f}")
print(f"Checking deviation of k={k} standard deviations (epsilon={epsilon:.2f})")
print(f"We want P(|X - {mu}| >= {epsilon:.2f}), which is P(X <= {lower_bound} or X >= {upper_bound})")
print(f"Actual Probability: {actual_prob:.4f}")
print(f"Chebyshev Bound: <= {chebyshev_bound:.4f}")
print(f"Is the actual probability less than or equal to the bound? {actual_prob <= chebyshev_bound}")
# Plot the distribution and the bounds
x_values = np.arange(0, n + 1)
pmf_values = binom.pmf(k=x_values, n=n, p=p)
plt.figure(figsize=(12, 6))
plt.bar(x_values, pmf_values, label='Binomial PMF', color='skyblue')
plt.axvline(mu, color='black', linestyle='--', label=f'Mean (mu={mu})')
plt.axvline(mu - epsilon, color='red', linestyle=':', label=f'mu - {k}*sigma ({mu - epsilon:.1f})')
plt.axvline(mu + epsilon, color='red', linestyle=':', label=f'mu + {k}*sigma ({mu + epsilon:.1f})')
plt.fill_between(x_values, pmf_values, where=(x_values <= lower_bound) | (x_values >= upper_bound),
color='red', alpha=0.5, label=f'Area where |X - mu| >= {k}*sigma')
plt.title("Binomial Distribution and Chebyshev's Bound (k=2)")
plt.xlabel("Number of Successes (X)")
plt.ylabel("Probability")
plt.legend()
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()Distribution: Binomial(n=100, p=0.5)
Mean (mu): 50.0, Standard Deviation (sigma): 5.00
Checking deviation of k=2 standard deviations (epsilon=10.00)
We want P(|X - 50.0| >= 10.00), which is P(X <= 40.0 or X >= 60.0)
Actual Probability: 0.0569
Chebyshev Bound: <= 0.2500
Is the actual probability less than or equal to the bound? True
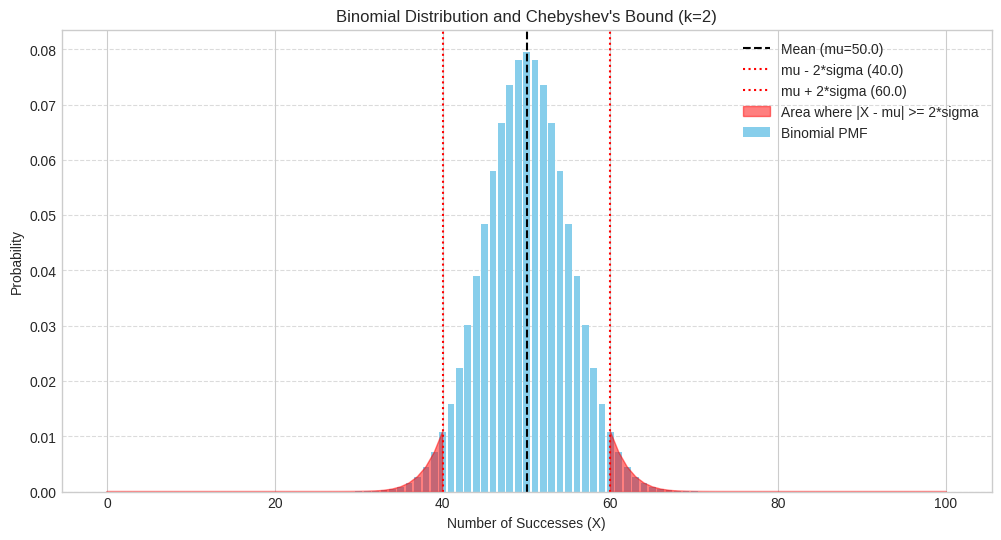
As we can see, the actual probability (around 0.0569) is much smaller than the Chebyshev bound (0.25). This illustrates that while the inequality always holds, it might not be very precise for specific, well-behaved distributions like the Binomial (which is close to Normal for these parameters).
The Law of Large Numbers (LLN)¶
Chebyshev’s inequality provides a foundation for proving one version of the Law of Large Numbers. The LLN formalizes the idea that sample averages converge to the population mean as the sample size increases.
Let be a sequence of independent and identically distributed (i.i.d.) random variables, each with the same finite mean and finite variance .
Let be the sample mean (average) of the first variables:
The LLN describes the behavior of as . There are two main versions:
1. Weak Law of Large Numbers (WLLN)¶
The WLLN states that the sample mean converges in probability to the true mean .
Definition (Convergence in Probability): A sequence of random variables converges in probability to a constant (written ) if, for every :
In words: As gets larger, the probability that is significantly different from becomes arbitrarily small.
Theorem (Weak Law of Large Numbers): If are i.i.d. with finite mean and finite variance , then the sample mean converges in probability to :
That is, for any :
Proof using Chebyshev’s Inequality: We need the properties of expected value and variance for the sample mean :
. (The expected value of the sample mean is the true mean).
. Since the are independent: . (The variance of the sample mean decreases as increases).
Now, apply Chebyshev’s Inequality to the random variable , which has mean and variance :
Taking the limit as :
Since probability cannot be negative, the limit must be exactly 0. This proves the WLLN under the condition of finite variance. (Note: The WLLN holds even if only the mean is finite, but the proof is more complex).
Intuition: The WLLN tells us that for a sufficiently large sample size n, the probability that the sample average deviates from the true mean by more than any small amount is very low.
2. Strong Law of Large Numbers (SLLN)¶
The SLLN makes a stronger statement about the convergence of the sample mean. It states that converges almost surely to .
Definition (Almost Sure Convergence): A sequence of random variables converges almost surely to a constant (written ) if:
In words: The probability that the sequence of values eventually converges to and stays at is 1. This means that for any specific realization (sequence of outcomes) of the random process, the sample average will converge to the true mean, except possibly for a set of outcomes with zero probability.
Theorem (Strong Law of Large Numbers - Kolmogorov): If are i.i.d. with finite mean , then the sample mean converges almost surely to :
(Note: The condition for the SLLN only requires finite mean, not finite variance, unlike our proof of the WLLN using Chebyshev).
WLLN vs SLLN:
WLLN concerns the probability of deviation for a specific large n. It doesn’t guarantee that convergence will happen for a particular sequence of outcomes.
SLLN concerns the behavior of the entire sequence of sample averages. It guarantees that the sample average will eventually converge to the true mean for almost every possible sequence of outcomes.
For most practical applications in simulation and statistics, the intuition provided by either law is similar: the sample average is a reliable estimator of the true expected value for large sample sizes.
Applications: Justification for Monte Carlo Methods¶
The Law of Large Numbers is the cornerstone of Monte Carlo simulation. Monte Carlo methods use repeated random sampling to obtain numerical results, often when analytical solutions are intractable.
Consider estimating a probability of some event . We can perform independent trials of the relevant experiment. Let be an indicator random variable for the -th trial: if event occurs on trial , if event does not occur on trial .
Then . The sample mean represents the proportion of times event occurred in the trials (the empirical probability).
By the LLN (either Weak or Strong), as :
So, the proportion of successes in a large number of trials converges to the true probability of success. This justifies using the observed frequency from a large simulation to estimate an unknown probability.
Similarly, if we want to estimate the expected value for some random variable and function , we can generate many i.i.d. samples from the distribution of . Let . Then . The sample mean of the transformed variables is:
By the LLN, as :
Thus, the average of over many simulations converges to the true expected value . This is the basis for Monte Carlo integration and estimating expected values of complex systems.
Hands-on: Simulating the Law of Large Numbers¶
Let’s visualize the LLN by simulating the rolling of a fair six-sided die. The random variable is the outcome of a single roll. The sample space is . The true mean (expected value) is:
We will simulate die rolls, calculate the running sample average after each roll, and plot how it converges towards the theoretical mean of 3.5.
import numpy as np
import matplotlib.pyplot as plt
# Configure plot style
plt.style.use('seaborn-v0_8-whitegrid')
# --- Simulation Parameters ---
num_rolls = 5000 # Total number of die rolls to simulate
true_mean = 3.5 # Theoretical expected value for a fair die
# --- Simulate Die Rolls ---
# Generate random integers between 1 and 6 (inclusive)
rolls = np.random.randint(1, 7, size=num_rolls)
# --- Calculate Running Average ---
# Calculate the cumulative sum of the rolls
cumulative_sum = np.cumsum(rolls)
# Calculate the number of rolls at each step (1, 2, 3, ..., num_rolls)
roll_numbers = np.arange(1, num_rolls + 1)
# Calculate the running average: cumulative_sum / number_of_rolls
running_average = cumulative_sum / roll_numbers
# --- Plotting ---
plt.figure(figsize=(12, 6))
# Plot the running average
plt.plot(roll_numbers, running_average, label='Running Sample Average')
# Plot the true mean
plt.axhline(true_mean, color='red', linestyle='--', label=f'True Mean ({true_mean})')
# Add annotations and labels
plt.title(f'Law of Large Numbers: Convergence of Sample Mean ({num_rolls} Die Rolls)')
plt.xlabel('Number of Rolls')
plt.ylabel('Sample Average')
plt.xlim(0, num_rolls)
# Adjust y-limits for better visualization if needed, e.g.:
# plt.ylim(1, 6)
plt.legend()
plt.grid(True)
# Optional: Show the plot for the first few rolls more clearly
plt.figure(figsize=(12, 6))
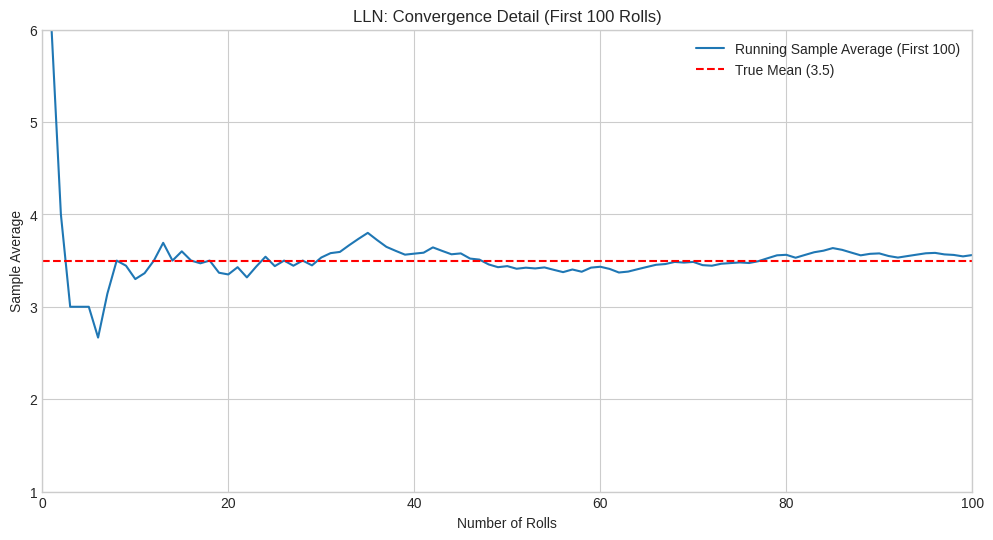
plt.plot(roll_numbers[:100], running_average[:100], label='Running Sample Average (First 100)')
plt.axhline(true_mean, color='red', linestyle='--', label=f'True Mean ({true_mean})')
plt.title('LLN: Convergence Detail (First 100 Rolls)')
plt.xlabel('Number of Rolls')
plt.ylabel('Sample Average')
plt.xlim(0, 100)
plt.ylim(1, 6) # Set fixed y-axis for fair comparison
plt.legend()
plt.grid(True)
plt.show()
print(f"Final sample average after {num_rolls} rolls: {running_average[-1]:.4f}")
print(f"Difference from true mean: {abs(running_average[-1] - true_mean):.4f}")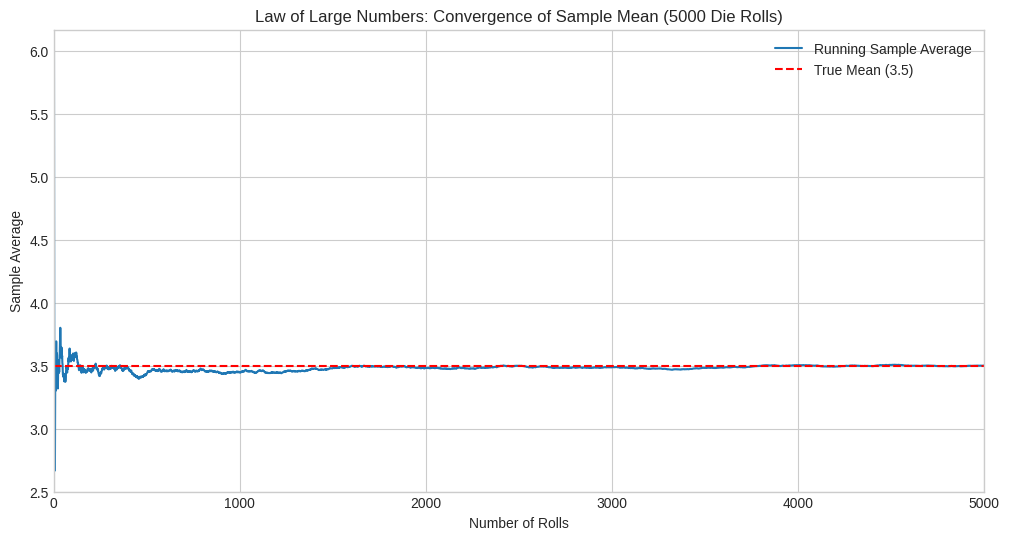
Final sample average after 5000 rolls: 3.5006
Difference from true mean: 0.0006
The plots clearly demonstrate the LLN in action. Initially, the sample average fluctuates significantly. However, as the number of rolls increases, the sample average stabilizes and gets progressively closer to the true expected value of 3.5. The final average after 5000 rolls is very close to the theoretical mean. This convergence is exactly what the LLN predicts.
Chapter Summary¶
Chebyshev’s Inequality provides a distribution-independent upper bound on the probability that a random variable deviates from its mean by a certain amount: . While often loose, it’s universally applicable given finite mean and variance.
The Law of Large Numbers (LLN) describes the convergence of the sample average () of i.i.d. random variables to the population mean () as the sample size () grows.
Weak Law of Large Numbers (WLLN): States that converges in probability to . This means as . It can be proven using Chebyshev’s inequality (if variance is finite).
Strong Law of Large Numbers (SLLN): States that converges almost surely to . This means . It’s a stronger condition, implying convergence for almost every specific sequence of outcomes.
Applications: The LLN is the fundamental justification for Monte Carlo methods, ensuring that averages calculated from large simulations reliably estimate true probabilities and expected values.
Simulation: We visualized the LLN by plotting the running average of simulated die rolls, observing its convergence towards the theoretical mean of 3.5.
The LLN tells us where the sample average converges (to the population mean). Our next topic, the Central Limit Theorem (CLT), will tell us about the shape of the distribution of the sample average around that mean for large sample sizes.
Exercises¶
Chebyshev vs. Reality (Exponential): Let . Recall and . a. Use Chebyshev’s inequality to find an upper bound for . (Here , so ). b. Calculate the exact probability using the CDF of the Exponential distribution ( for ). c. Compare the bound from (a) with the exact value from (b).
Simulating LLN for Bernoulli: Consider a Bernoulli trial with (probability of success). The true mean is . a. Simulate 10,000 Bernoulli trials with . b. Calculate and plot the running average of the outcomes (which represents the empirical probability of success). c. Verify visually that the running average converges towards 0.3.
Convergence Rate: In the proof of WLLN using Chebyshev, we found . If we want to ensure this probability bound is less than 0.01 for , how large does need to be for the die roll example ()? Does this seem like a practical sample size based on the simulation?