In the previous chapter, we defined discrete random variables and learned how to describe their behavior using Probability Mass Functions (PMFs), Cumulative Distribution Functions (CDFs), expected value, and variance. While we can define custom PMFs for any situation, several specific discrete distributions appear so frequently in practice that they have been studied extensively and given names.
These “common” distributions serve as powerful models for a wide variety of real-world processes. Understanding their properties and when to apply them is crucial for probabilistic modeling. In this chapter, we will explore nine fundamental discrete distributions: Bernoulli, Binomial, Geometric, Negative Binomial, Poisson, Hypergeometric, Discrete Uniform, Categorical, and Multinomial.
We’ll examine the scenarios each distribution models, their key characteristics (PMF, mean, variance), and how to work with them efficiently using Python’s scipy.stats library. This library provides tools to calculate probabilities (PMF, CDF), generate random samples, and more, significantly simplifying our practical work.
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import os
# Configure plots
plt.style.use('seaborn-v0_8-whitegrid')
The Bernoulli distribution models a single trial with two possible outcomes: “success” (1) or “failure” (0).
Concrete Example
Suppose you’re conducting a medical screening test for a disease in a high-risk population. Each test either shows positive or negative. From epidemiological data, you know that 30% of individuals in this population test positive.
We model this with a random variable X:
X=1 if the test result is positive (success)
X=0 if the test result is negative (failure)
The probabilities are:
P(X=1)=0.3 (we call this parameter p)
P(X=0)=0.7 (which equals 1−p)
The Bernoulli PMF
For any Bernoulli random variable with success probability p, the PMF is:
Let’s verify this works for our example where p=0.3:
When k=1: P(X=1)=(0.3)1(0.7)0=0.3×1=0.3 ✓
When k=0: P(X=0)=(0.3)0(0.7)1=1×0.7=0.7 ✓
Key Characteristics
Scenarios: Coin flip (Heads/Tails), product inspection (Defective/Not Defective), medical test (Positive/Negative), free throw (Make/Miss)
Parameter: p, the probability of success (0≤p≤1)
Random Variable: X∈{0,1}
Mean:E[X]=p
Variance:Var(X)=p(1−p)
Standard Deviation:SD(X)=p(1−p)
Visualizing the Distribution
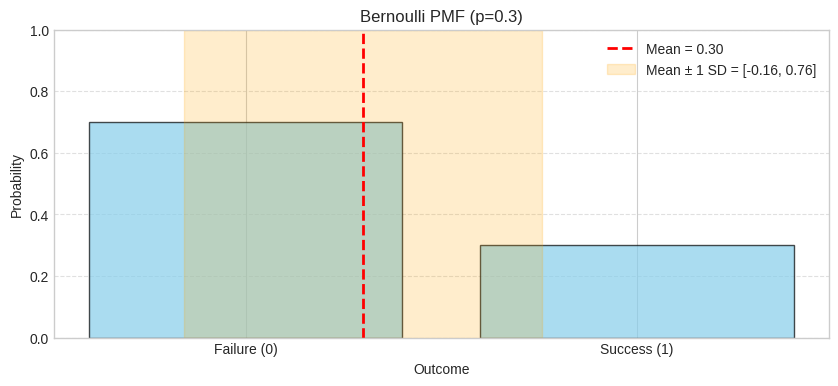
Let’s visualize a Bernoulli distribution with p=0.3 (our medical test example from above):
# Remove existing SVG if present
if os.path.exists('ch07_bernoulli_pmf_generic.svg'):
os.remove('ch07_bernoulli_pmf_generic.svg')
# Create Bernoulli distribution for visualization (p=0.3)
p_viz = 0.3
bernoulli_viz = stats.bernoulli(p=p_viz)
# Calculate mean and std
mean_viz = bernoulli_viz.mean()
std_viz = bernoulli_viz.std()
# Plotting the PMF
k_values_viz = [0, 1]
pmf_values_viz = bernoulli_viz.pmf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.bar(k_values_viz, pmf_values_viz, tick_label=["Failure (0)", "Success (1)"], color='skyblue', edgecolor='black', alpha=0.7)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.2f}')
# Add mean ± 1 std region
plt.axvspan(mean_viz - std_viz, mean_viz + std_viz, alpha=0.2, color='orange',
label=f'Mean ± 1 SD = [{mean_viz - std_viz:.2f}, {mean_viz + std_viz:.2f}]')
plt.title(f"Bernoulli PMF (p={p_viz})")
plt.xlabel("Outcome")
plt.ylabel("Probability")
plt.ylim(0, 1)
plt.legend(loc='upper right', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.savefig('ch07_bernoulli_pmf_generic.svg', format='svg', bbox_inches='tight')
plt.show()
The PMF shows two bars: P(X=0) = 0.7 for a negative test and P(X=1) = 0.3 for a positive test. The red dashed line marks the mean (p=0.3), and the orange shaded region shows mean ± 1 standard deviation.
# Remove existing SVG if present
if os.path.exists('ch07_bernoulli_cdf_generic.svg'):
os.remove('ch07_bernoulli_cdf_generic.svg')
# Plotting the CDF
k_values_viz = [0, 1]
cdf_values_viz = bernoulli_viz.cdf(k_values_viz)
plt.figure(figsize=(10, 4))
# Add points to show the full step function including the start at 0
plt.step([-0.5] + k_values_viz, [0] + list(cdf_values_viz), where='post', color='darkgreen', linewidth=2)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.2f}')
plt.title(f"Bernoulli CDF (p={p_viz})")
plt.xlabel("Outcome")
plt.ylabel("Cumulative Probability P(X <= k)")
plt.ylim(0, 1.1)
plt.xlim(-0.5, 1.5)
plt.xticks([0, 1])
plt.legend(loc='lower right', fontsize=10)
plt.grid(True, which='both', linestyle='--', linewidth=0.5, alpha=0.6)
plt.savefig('ch07_bernoulli_cdf_generic.svg', format='svg', bbox_inches='tight')
plt.show()
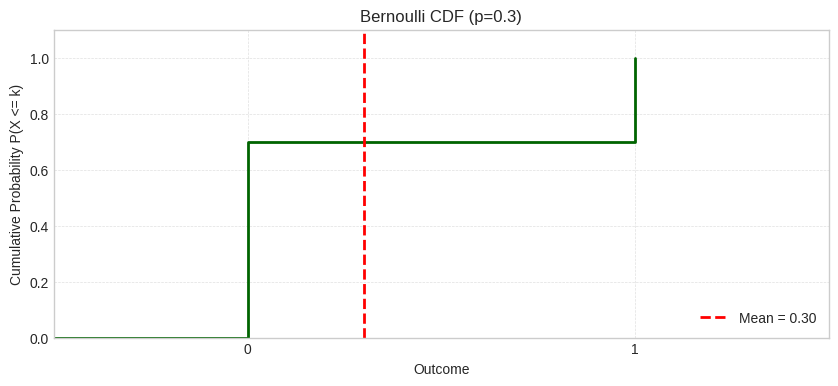
The CDF shows the step function: starts at 0 for x < 0, jumps to 0.7 at x=0 (the value when outcome is 0), stays flat at 0.7 until x=1, then jumps to 1.0 at x=1 (the value when including both outcomes 0 and 1). The red dashed line marks the mean.
Note: Here, P(X ≤ 0) = P(X = 0) = 0.7 because X can’t take negative values; in general, “X ≤ 0” means “at or below 0”, not “exactly 0”.
Reading the PMF
What it shows: The height of each bar represents the probability of that exact outcome
How to read: Look at the bar height to find P(X = k) for any specific value k
Practical use: Answer questions like “What’s the probability of success?” or “What’s the probability of exactly 1 positive test?”
Key property: All bar heights must sum to 1.0 (total probability)
Visualization aids: The red dashed line marks the mean (expected value), and the orange shaded region shows mean ± 1 standard deviation (where ~68% of values typically fall)
Reading the CDF
What it shows: The cumulative probability P(X ≤ k) up to and including each value k
How to read: The height at position k tells you the probability of getting k or fewer successes
Why step functions? For discrete distributions, probability accumulates in jumps at each possible value. Between possible values, the CDF stays constant (no additional probability)
Key identity: The jump at k equals P(X = k) — the size of each step up is the PMF value
Practical uses:
Find P(X ≤ k) directly by reading the height at k
Find P(X > k) by calculating 1 - P(X ≤ k)
Find P(a < X ≤ b) by calculating P(X ≤ b) - P(X ≤ a)
Key property: The CDF is right-continuous, always increases (or stays flat), and approaches 1.0
Visualization aids: The red dashed line marks the mean (expected value) as a reference point
Note on CDF visualization: The charts use where='post' in the step plot to create proper right-continuous step functions. This means the CDF jumps up at each value and includes that value in the cumulative probability.
Quick Check Questions
A quality control inspector checks a single product. It’s either defective or not defective. Is this scenario well-modeled by a Bernoulli distribution? Why or why not?
Answer
Yes - This scenario perfectly fits the Bernoulli distribution requirements:
Single trial: Checking one product
Two possible outcomes: Defective (success/1) or not defective (failure/0)
Fixed probability: The defect rate is constant for each product
If the defect rate is 5%, we’d use Bernoulli(p=0.05).
For a Bernoulli distribution with p = 0.3, what is P(X = 0)?
Answer
P(X = 0) = 1 - p = 0.7 - The probability of failure is 1 - p.
A basketball player has a 75% free throw success rate. If we model a single free throw as a Bernoulli trial, what are the mean and variance?
Answer
Mean = 0.75, Variance = 0.75 × 0.25 = 0.1875
Using the formulas E[X] = p and Var(X) = p(1-p):
E[X] = 0.75
Var(X) = 0.75 × (1 - 0.75) = 0.75 × 0.25 = 0.1875
You roll a six-sided die once. Is this well-modeled by a Bernoulli distribution?
Answer
No - A Bernoulli distribution requires exactly two possible outcomes. A die roll has 6 outcomes (1, 2, 3, 4, 5, 6), so Bernoulli doesn’t apply directly.
However, you could use Bernoulli if you redefined the experiment with a binary outcome:
“Does the die show a 6?” (Yes/No) → Bernoulli with p = 1/6
“Is the result even?” (Yes/No) → Bernoulli with p = 1/2
The key: Bernoulli requires exactly two outcomes.
True or False: A Bernoulli random variable can only take on the values 0 and 1.
Answer
True - By definition, a Bernoulli random variable X ∈ {0, 1}, where:
The Binomial distribution models the number of successes in a fixed number of independent Bernoulli trials, where each trial has the same probability of success.
Concrete Example
Suppose you flip a fair coin 10 times. Each flip is a Bernoulli trial with p = 0.5 (probability of heads). How many heads will you get?
We model this with a random variable X:
X = the number of heads in 10 flips
X can take values 0, 1, 2, ..., 10
The probabilities are:
P(X=0) = probability of 0 heads (all tails)
P(X=5) = probability of exactly 5 heads
P(X=10) = probability of 10 heads (all heads)
The Binomial PMF
For n independent trials with success probability p:
Scenarios: Number of heads in coin flips, defective items in a batch, successful free throws, correct guesses on a test, customers who purchase
Parameters:
n: number of independent trials
p: probability of success on each trial (0≤p≤1)
Random Variable: X∈{0,1,2,...,n}
Mean:E[X]=np
Variance:Var(X)=np(1−p)
Standard Deviation:SD(X)=np(1−p)
Visualizing the Distribution
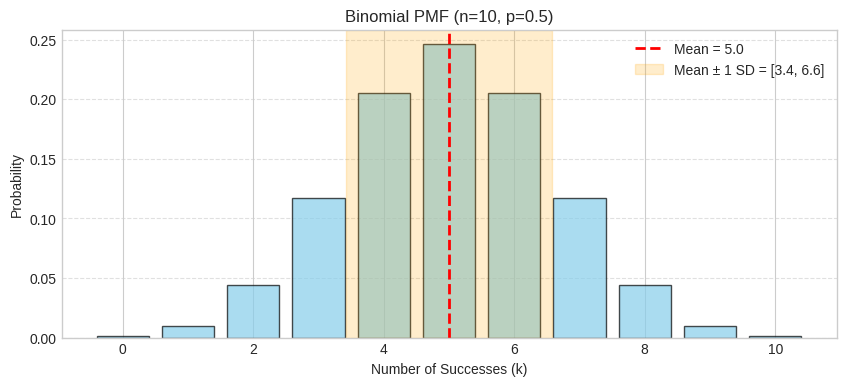
Let’s visualize a Binomial distribution with n=10 and p=0.5 (our coin flip example):
# Remove existing SVG if present
if os.path.exists('ch07_binomial_pmf_generic.svg'):
os.remove('ch07_binomial_pmf_generic.svg')
# Create Binomial distribution for visualization (n=10, p=0.5)
n_viz = 10
p_viz = 0.5
binomial_viz = stats.binom(n=n_viz, p=p_viz)
# Calculate mean and std
mean_viz = binomial_viz.mean()
std_viz = binomial_viz.std()
# Plotting the PMF
k_values_viz = np.arange(0, n_viz + 1)
pmf_values_viz = binomial_viz.pmf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.bar(k_values_viz, pmf_values_viz, color='skyblue', edgecolor='black', alpha=0.7)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.1f}')
# Add mean ± 1 std region
plt.axvspan(mean_viz - std_viz, mean_viz + std_viz, alpha=0.2, color='orange',
label=f'Mean ± 1 SD = [{mean_viz - std_viz:.1f}, {mean_viz + std_viz:.1f}]')
plt.title(f"Binomial PMF (n={n_viz}, p={p_viz})")
plt.xlabel("Number of Successes (k)")
plt.ylabel("Probability")
plt.legend(loc='upper right', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.savefig('ch07_binomial_pmf_generic.svg', format='svg', bbox_inches='tight')
plt.show()
The PMF shows the probability distribution for the number of heads in 10 coin flips. The distribution is symmetric around the mean (np=5) since p=0.5. The shaded region shows mean ± 1 standard deviation (np(1−p)=2.5≈1.58).
# Remove existing SVG if present
if os.path.exists('ch07_binomial_cdf_generic.svg'):
os.remove('ch07_binomial_cdf_generic.svg')
# Plotting the CDF
cdf_values_viz = binomial_viz.cdf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.step(k_values_viz, cdf_values_viz, where='post', color='darkgreen', linewidth=2)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.1f}')
plt.title(f"Binomial CDF (n={n_viz}, p={p_viz})")
plt.xlabel("Number of Successes (k)")
plt.ylabel("Cumulative Probability P(X <= k)")
plt.legend(loc='lower right', fontsize=10)
plt.grid(True, which='both', linestyle='--', linewidth=0.5, alpha=0.6)
plt.savefig('ch07_binomial_cdf_generic.svg', format='svg', bbox_inches='tight')
plt.show()
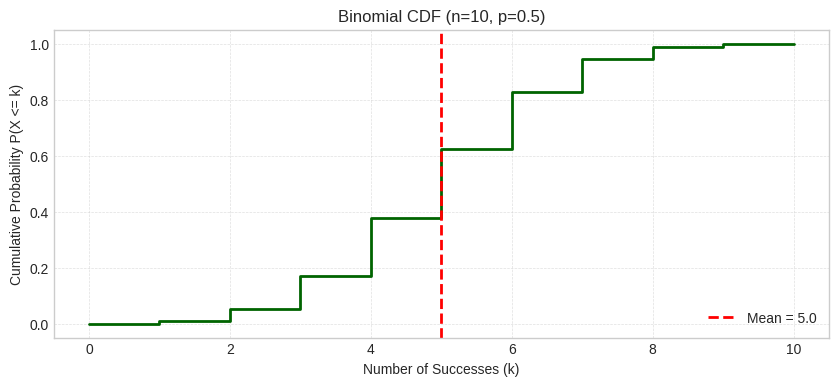
The CDF shows P(X ≤ k), the cumulative probability of getting k or fewer heads. The red dashed line marks the mean.
Quick Check Questions
You roll a die 12 times and count how many times you get a 6. Is this a good fit for the Binomial distribution? Why or why not?
Answer
Yes, this is a good fit for Binomial. It satisfies all the requirements: (1) fixed number of trials (n = 12 rolls), (2) each trial is independent, (3) only two outcomes per trial (rolling a 6 vs not rolling a 6), and (4) constant success probability (p = 1/6 for each roll). The parameters would be n = 12 and p = 1/6.
For a Binomial distribution with n = 8 and p = 0.25, what is the expected value (mean)?
Answer
E[X] = np = 8 × 0.25 = 2 - The expected number of successes in 8 trials is 2.
A basketball player has a 70% free throw success rate. You watch her take 15 free throws. Does this scenario fit the Binomial distribution assumptions?
Answer
Yes, this fits the Binomial distribution with n = 15 and p = 0.7. Each free throw is independent, has two outcomes (make or miss), and the success probability remains constant at 0.7 for each attempt. We can use this to calculate probabilities like “What’s the chance she makes at least 12 out of 15?”
For a Binomial(n=20, p=0.3) distribution, what is the variance?
Answer
Var(X) = np(1-p) = 20 × 0.3 × 0.7 = 4.2
Using the variance formula for Binomial distributions.
True or False: In a Binomial distribution, each trial must have the same probability of success.
Answer
True - The Binomial distribution requires:
Fixed number of independent trials (n)
Each trial has only two outcomes (success/failure)
Constant success probability (p) across all trials
Trials are independent
If the success probability changes from trial to trial, Binomial doesn’t apply.
The Geometric distribution models the number of independent Bernoulli trials needed to get the first success.
Concrete Example
You’re shooting free throws until you make your first basket. Each shot has a 0.4 probability of success. How many shots will it take to make your first basket?
We model this with a random variable X:
X = the trial number on which the first success occurs
X can take values 1, 2, 3, ... (first shot, second shot, etc.)
The probabilities are:
P(X=1) = make it on first shot = 0.4
P(X=2) = miss first, make second = (1−0.4)×0.4=0.24
P(X=3) = miss first two, make third = (1−0.4)2×0.4=0.144
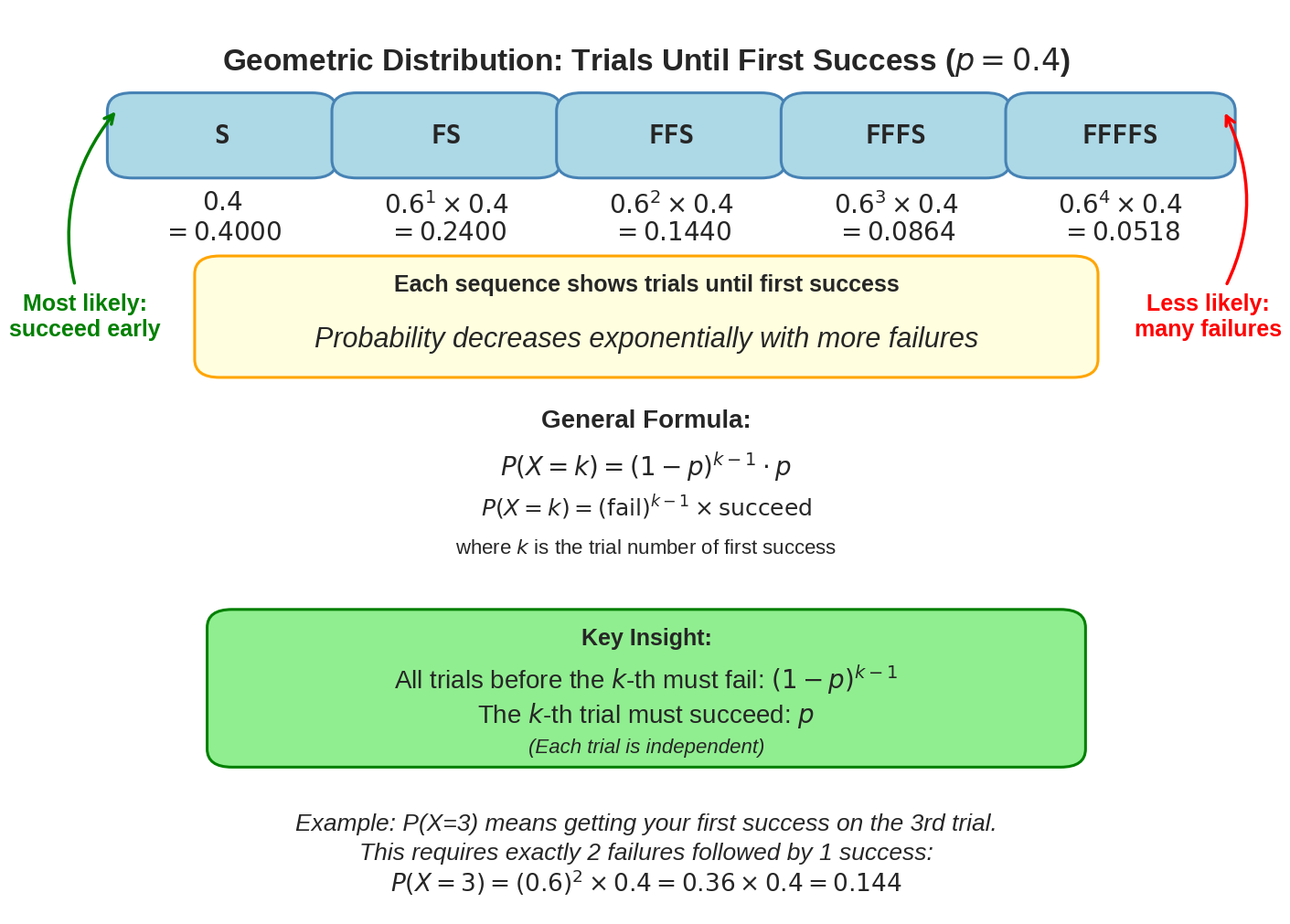
The diagram shows how the geometric distribution works: each additional failure before success makes the outcome less likely. The probability decreases exponentially - notice how P(X=1) = 0.4000 is much larger than P(X=5) = 0.0518.
Key Characteristics
Scenarios: Coin flips until first Head, job applications until first offer, attempts to pass an exam, at-bats until first hit
Parameter: p, probability of success on each trial (0<p≤1)
Random Variable: X∈{1,2,3,...}
Mean:E[X]=p1
Variance:Var(X)=p21−p
Standard Deviation:SD(X)=p1−p
Relationship to Other Distributions: The Geometric distribution is built from independent Bernoulli trials and is a special case of the Negative Binomial distribution with r=1 (waiting for just one success instead of r successes).
Visualizing the Distribution
Let’s visualize a Geometric distribution with p=0.4 (our free throw example):
# Remove existing SVG if present
if os.path.exists('ch07_geometric_pmf_generic.svg'):
os.remove('ch07_geometric_pmf_generic.svg')
# Create Geometric distribution for visualization (p=0.4)
p_viz = 0.4
geom_viz = stats.geom(p=p_viz)
# Calculate mean and std (adjusted for trial number definition)
mean_viz = 1 / p_viz
std_viz = np.sqrt((1 - p_viz) / p_viz**2)
# Plotting the PMF
k_values_viz = np.arange(1, 11)
pmf_values_viz = geom_viz.pmf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.bar(k_values_viz, pmf_values_viz, color='skyblue', edgecolor='black', alpha=0.7)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.2f}')
# Add mean ± 1 std region
plt.axvspan(mean_viz - std_viz, mean_viz + std_viz, alpha=0.2, color='orange',
label=f'Mean ± 1 SD = [{mean_viz - std_viz:.1f}, {mean_viz + std_viz:.1f}]')
plt.title(f"Geometric PMF (p={p_viz})")
plt.xlabel("Trial Number (k)")
plt.ylabel("Probability P(X=k)")
plt.xticks(k_values_viz)
plt.legend(loc='upper right', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.savefig('ch07_geometric_pmf_generic.svg', format='svg', bbox_inches='tight')
plt.show()
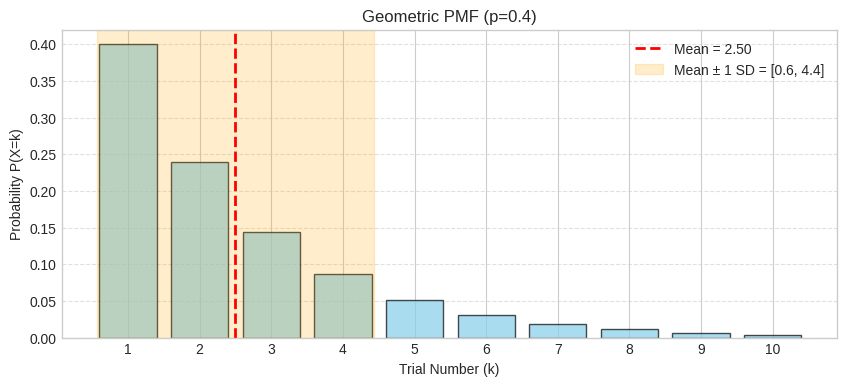
The PMF shows exponentially decreasing probabilities - you’re most likely to succeed on the first few trials. The shaded region shows mean ± 1 standard deviation.
# Remove existing SVG if present
if os.path.exists('ch07_geometric_cdf_generic.svg'):
os.remove('ch07_geometric_cdf_generic.svg')
# Plotting the CDF
cdf_values_viz = geom_viz.cdf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.step(k_values_viz, cdf_values_viz, where='post', color='darkgreen', linewidth=2)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.2f}')
plt.title(f"Geometric CDF (p={p_viz})")
plt.xlabel("Trial Number (k)")
plt.ylabel("Cumulative Probability P(X <= k)")
plt.xticks(k_values_viz)
plt.legend(loc='lower right', fontsize=10)
plt.grid(True, which='both', linestyle='--', linewidth=0.5, alpha=0.6)
plt.savefig('ch07_geometric_cdf_generic.svg', format='svg', bbox_inches='tight')
plt.show()
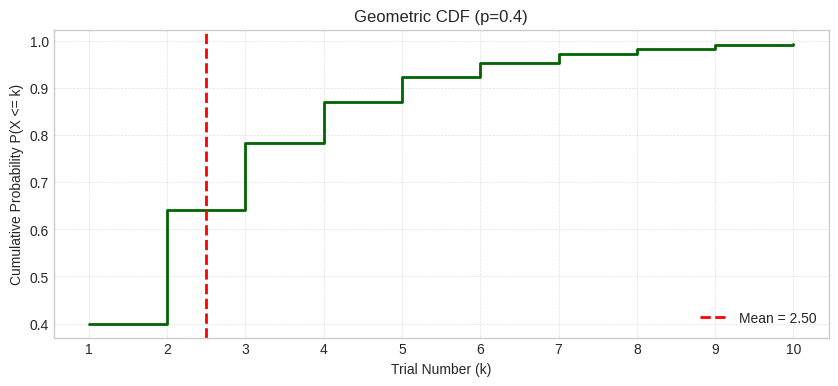
The CDF shows P(X ≤ k), approaching 1 as k increases (eventually you’ll succeed). The red dashed line marks the mean.
Quick Check Questions
You flip a coin until you get your first Heads. What distribution models this and what is the parameter?
Answer
Geometric distribution with p = 0.5 - Counting trials until first success, each trial has p = 0.5 success probability.
For a Geometric distribution with p = 0.25, what is the expected value (mean)?
Answer
E[X] = 1/p = 1/0.25 = 4 - Expected number of trials until first success.
You’re calling customer service and have a 20% chance each attempt of getting through. Should you model this with Geometric or Binomial?
Answer
Geometric distribution - You’re waiting for the first success (getting through), not counting successes in a fixed number of tries. Geometric models “how many attempts until success” with p = 0.20.
Binomial would apply if you made a fixed number of calls and counted how many got through.
Which is more likely for a Geometric distribution with p = 0.5: success on the 1st trial or success on the 3rd trial?
Answer
1st trial is more likely - The Geometric PMF decreases exponentially with k, so P(X=1) > P(X=3).
Specifically: P(X=1) = 0.5, while P(X=3) = (0.5)³ = 0.125
For a Geometric distribution, why does the variance equal (1-p)/p²?
Answer
The variance formula Var(X) = (1-p)/p² reflects the increasing uncertainty as p decreases:
When p is high (easy to succeed): variance is low (more predictable)
When p is low (hard to succeed): variance is high (could take many tries or get lucky early)
For example:
p = 0.5: Var(X) = 0.5/0.25 = 2
p = 0.1: Var(X) = 0.9/0.01 = 90 (much more variable!)
The Negative Binomial distribution models the number of independent Bernoulli trials needed to achieve a fixed number of successes (r). It generalizes the Geometric distribution (where r=1).
Concrete Example
You’re rolling a die until you get 3 sixes. Each roll has p = 1/6 probability of rolling a six. How many rolls will it take to get your 3rd six?
We model this with a random variable X:
X = the trial number on which the 3rd six appears
X can take values 3, 4, 5, ... (minimum 3 rolls, could be more)
The probabilities are:
P(X=3) = all three rolls are sixes
P(X=4) = 2 sixes in first 3 rolls, then a six on 4th roll
And so on...
The Negative Binomial PMF
For trials with success probability p and target r successes:
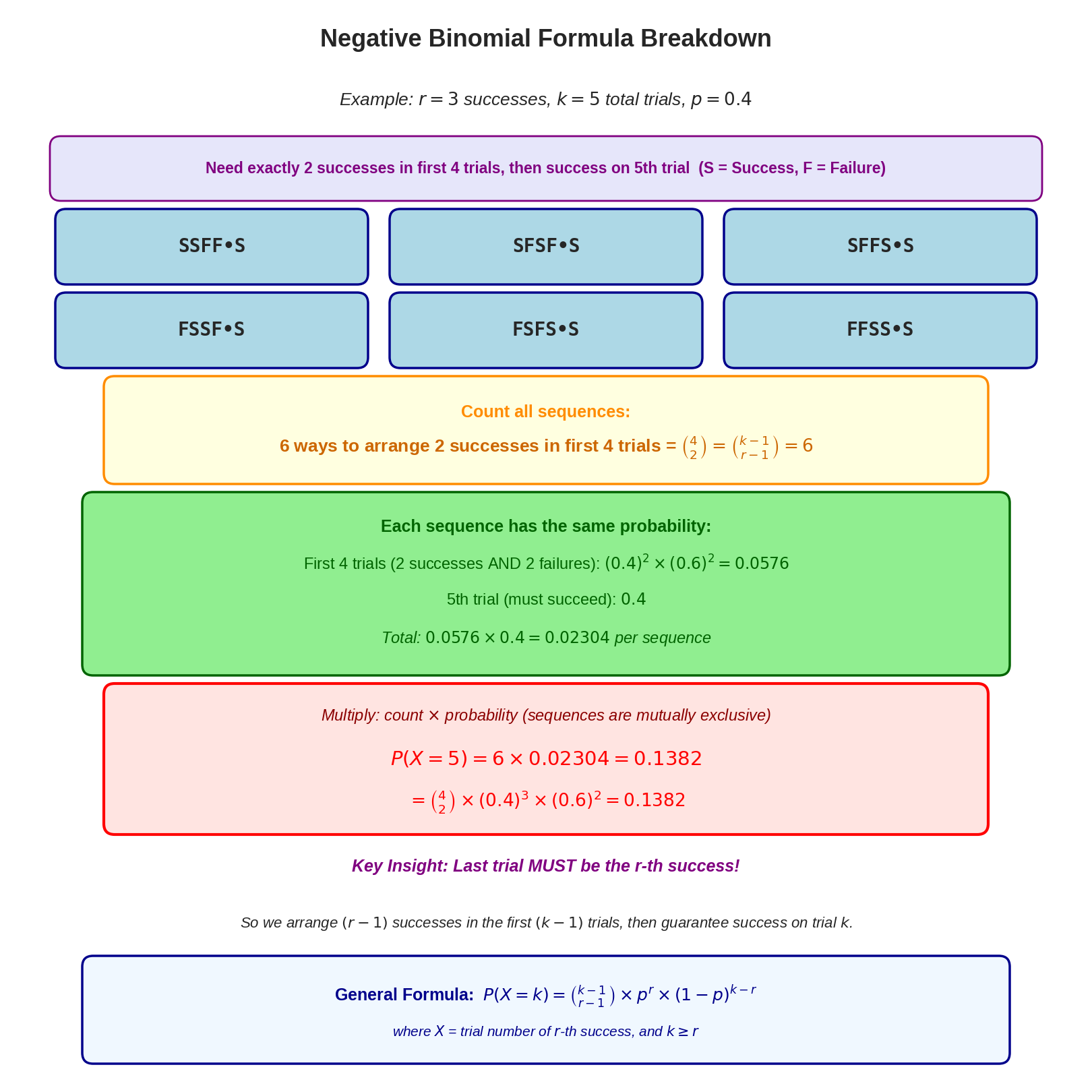
Understanding the formula: This means r−1 successes in the first k−1 trials, and the k-th trial is the r-th success.
Visual breakdown: The following diagram shows how the negative binomial formula counts all possible sequences and combines their probabilities:
# Remove existing SVG if present
if os.path.exists('ch07_negative_binomial_formula_breakdown.svg'):
os.remove('ch07_negative_binomial_formula_breakdown.svg')
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
# --- Settings ---
BOX_PAD = 0.01 # single, consistent pad for every rounded box (fixes uneven visible gaps)
# Create figure for formula breakdown
fig, ax = plt.subplots(figsize=(16, 16))
# Make axes fill the whole figure so "axes coords" behave predictably
fig.subplots_adjust(left=0, right=1, top=1, bottom=0)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.axis('off')
# Define all CONTENT heights (actual elements)
title_height = 0.03
subtitle_height = 0.025
param_box_height = 0.04
seq_box_height = 0.05
count_box_height = 0.08
prob_box_height = 0.15
result_box_height = 0.12
key_insight_text_height = 0.025
key_explain_text_height = 0.025
formula_box_height = 0.08
# Calculate total content height
total_content_height = (
title_height +
subtitle_height +
param_box_height +
seq_box_height * 2 + # Two rows of sequence boxes
count_box_height +
prob_box_height +
result_box_height +
key_insight_text_height +
key_explain_text_height +
formula_box_height
)
# Calculate available space for gaps
top_margin = 0.02
bottom_margin = 0.03
usable_height = 1.0 - top_margin - bottom_margin
whitespace = usable_height - total_content_height
# Number of gaps between sections
num_gaps = 10
# Calculate uniform gap size
gap = whitespace / num_gaps
def add_box(x, y, w, h, edge, face, lw, z=1):
"""Consistent rounded box with a single pad value."""
patch = mpatches.FancyBboxPatch(
(x, y), w, h,
boxstyle=f"round,pad={BOX_PAD}",
linewidth=lw,
edgecolor=edge,
facecolor=face,
zorder=z
)
ax.add_patch(patch)
return patch
# Build layout from top down with calculated gaps
current_y = 1.0 - top_margin
# Title
ax.text(0.5, current_y, "Negative Binomial Formula Breakdown",
transform=ax.transAxes, ha="center", va="top",
fontsize=26, weight="bold")
current_y -= title_height + gap
# Subtitle
ax.text(0.5, current_y, r"Example: $r=3$ successes, $k=5$ total trials, $p=0.4$",
transform=ax.transAxes, ha="center", va="top",
fontsize=19, style="italic")
current_y -= subtitle_height + gap
# Parameters box
param_box_bottom = current_y - param_box_height
add_box(0.05, param_box_bottom, 0.90, param_box_height,
edge='purple', face='lavender', lw=2, z=1)
ax.text(0.5, param_box_bottom + param_box_height/2,
"Need exactly 2 successes in first 4 trials, then success on 5th trial (S = Success, F = Failure)",
transform=ax.transAxes, ha="center", va="center",
fontsize=16.5, weight="bold", color="purple")
current_y = param_box_bottom - gap
# Sequence boxes - First row
sequences = ["SSFF•S", "SFSF•S", "SFFS•S", "FSSF•S", "FSFS•S", "FFSS•S"]
seq_row1_bottom = current_y - seq_box_height
for i in range(3):
x_pos = 0.055 + i * 0.31
add_box(x_pos, seq_row1_bottom, 0.27, seq_box_height,
edge='darkblue', face='lightblue', lw=2.5, z=2)
ax.text(x_pos + 0.135, seq_row1_bottom + seq_box_height/2, sequences[i],
transform=ax.transAxes, ha="center", va="center",
fontsize=20, weight="bold", family='monospace', zorder=3)
# Sequence boxes - Second row
current_y = seq_row1_bottom - gap
seq_row2_bottom = current_y - seq_box_height
for i in range(3):
x_pos = 0.055 + i * 0.31
add_box(x_pos, seq_row2_bottom, 0.27, seq_box_height,
edge='darkblue', face='lightblue', lw=2.5, z=2)
ax.text(x_pos + 0.135, seq_row2_bottom + seq_box_height/2, sequences[i+3],
transform=ax.transAxes, ha="center", va="center",
fontsize=20, weight="bold", family='monospace', zorder=3)
current_y = seq_row2_bottom - gap
# Counting explanation box
count_box_bottom = current_y - count_box_height
add_box(0.10, count_box_bottom, 0.80, count_box_height,
edge='darkorange', face='lightyellow', lw=2.5, z=1)
ax.text(0.5, count_box_bottom + count_box_height * 0.70, r"Count all sequences:",
transform=ax.transAxes, ha="center", va="center",
fontsize=18, weight="bold", color='darkorange', zorder=4)
ax.text(0.5, count_box_bottom + count_box_height * 0.30,
r"6 ways to arrange 2 successes in first 4 trials = $\binom{4}{2} = \binom{k-1}{r-1} = 6$",
transform=ax.transAxes, ha="center", va="center",
fontsize=19, weight="bold", color='#CC6600', zorder=4)
current_y = count_box_bottom - gap
# Probability calculation box
prob_box_bottom = current_y - prob_box_height
add_box(0.08, prob_box_bottom, 0.84, prob_box_height,
edge='darkgreen', face='lightgreen', lw=2.5, z=1)
ax.text(0.5, prob_box_bottom + prob_box_height * 0.85,
"Each sequence has the same probability:",
transform=ax.transAxes, ha="center", va="center",
fontsize=18, weight="bold", color='darkgreen', zorder=4)
ax.text(0.5, prob_box_bottom + prob_box_height * 0.62,
r"First 4 trials (2 successes AND 2 failures): $(0.4)^2 \times (0.6)^2 = 0.0576$",
transform=ax.transAxes, ha="center", va="center",
fontsize=17, color='darkgreen', zorder=4)
ax.text(0.5, prob_box_bottom + prob_box_height * 0.40,
r"5th trial (must succeed): $0.4$",
transform=ax.transAxes, ha="center", va="center",
fontsize=17, color='darkgreen', zorder=4)
ax.text(0.5, prob_box_bottom + prob_box_height * 0.16,
r"Total: $0.0576 \times 0.4 = 0.02304$ per sequence",
transform=ax.transAxes, ha="center", va="center",
fontsize=17, style="italic", color='darkgreen', zorder=4)
current_y = prob_box_bottom - gap
# Final result box
result_box_bottom = current_y - result_box_height
add_box(0.10, result_box_bottom, 0.80, result_box_height,
edge='red', face='mistyrose', lw=3, z=1)
ax.text(0.5, result_box_bottom + result_box_height * 0.83,
r"Multiply: count $\times$ probability (sequences are mutually exclusive)",
transform=ax.transAxes, ha="center", va="center",
fontsize=17, style="italic", color='darkred', zorder=4)
ax.text(0.5, result_box_bottom + result_box_height * 0.50,
r"$P(X=5) = 6 \times 0.02304 = 0.1382$",
transform=ax.transAxes, ha="center", va="center",
fontsize=21, weight="bold", color='red', zorder=4)
ax.text(0.5, result_box_bottom + result_box_height * 0.17,
r"$= \binom{4}{2} \times (0.4)^3 \times (0.6)^2 = 0.1382$",
transform=ax.transAxes, ha="center", va="center",
fontsize=19, color='red', zorder=4)
current_y = result_box_bottom - gap
# Key insight text
key_insight_y = current_y - key_insight_text_height/2
ax.text(0.5, key_insight_y,
"Key Insight: Last trial MUST be the r-th success!",
transform=ax.transAxes, ha="center", va="center",
fontsize=18, style="italic", weight="bold", color='purple', zorder=4)
current_y -= key_insight_text_height + gap
# Explanation text
key_explain_y = current_y - key_explain_text_height/2
ax.text(0.5, key_explain_y,
r"So we arrange $(r-1)$ successes in the first $(k-1)$ trials, then guarantee success on trial $k$.",
transform=ax.transAxes, ha="center", va="center",
fontsize=16, style="italic", zorder=4)
current_y -= key_explain_text_height + gap
# General formula box
formula_box_bottom = current_y - formula_box_height
add_box(0.08, formula_box_bottom, 0.84, formula_box_height,
edge='darkblue', face='aliceblue', lw=2.5, z=1)
ax.text(0.5, formula_box_bottom + formula_box_height * 0.65,
r"General Formula: $P(X = k) = \binom{k-1}{r-1} \times p^r \times (1-p)^{k-r}$",
transform=ax.transAxes, ha="center", va="center",
fontsize=18, weight="bold", color='darkblue', zorder=4)
ax.text(0.5, formula_box_bottom + formula_box_height * 0.25,
r"where $X$ = trial number of $r$-th success, and $k \geq r$",
transform=ax.transAxes, ha="center", va="center",
fontsize=15, style="italic", color='darkblue', zorder=4)
plt.savefig('ch07_negative_binomial_formula_breakdown.svg', format='svg', bbox_inches='tight', pad_inches=0.25)
plt.show()
The diagram shows how the negative binomial formula works: we need exactly r−1 successes in the first k−1 trials (which can be arranged in (r−1k−1) ways), and then the k-th trial must be a success. Each of the 6 sequences shown has the same probability, and we multiply by the number of sequences to get the total probability.
Now that we understand the formula and its visualization, let’s summarize the essential properties of the negative binomial distribution:
Key Characteristics
Scenarios: Coin flips until getting r Heads, products inspected to find r defects, interviews until making r hires
Parameters:
r: target number of successes (r≥1)
p: probability of success on each trial (0<p≤1)
Random Variable: X∈{r,r+1,r+2,...}
Mean:E[X]=pr
Variance:Var(X)=p2r(1−p)
Standard Deviation:SD(X)=pr(1−p)
Visualizing the Distribution
Let’s visualize our die example: Negative Binomial distribution with r=3 sixes and p=1/6:
# Remove existing SVG if present
if os.path.exists('ch07_negative_binomial_pmf_generic.svg'):
os.remove('ch07_negative_binomial_pmf_generic.svg')
# Create Negative Binomial distribution for our die example (r=3, p=1/6)
r_viz = 3
p_viz = 1/6
nbinom_viz = stats.nbinom(n=r_viz, p=p_viz)
# Calculate mean and std
mean_viz = r_viz / p_viz
std_viz = np.sqrt(r_viz * (1 - p_viz)) / p_viz
# Plotting the PMF
k_values_viz = np.arange(r_viz, 45) # Total trials from r to 45 (wider range for p=1/6)
pmf_values_viz = nbinom_viz.pmf(k_values_viz - r_viz) # Adjust for scipy
plt.figure(figsize=(10, 4))
plt.bar(k_values_viz, pmf_values_viz, color='skyblue', edgecolor='black', alpha=0.7)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.1f}')
# Add mean ± 1 std region
plt.axvspan(mean_viz - std_viz, mean_viz + std_viz, alpha=0.2, color='orange',
label=f'Mean ± 1 SD = [{mean_viz - std_viz:.1f}, {mean_viz + std_viz:.1f}]')
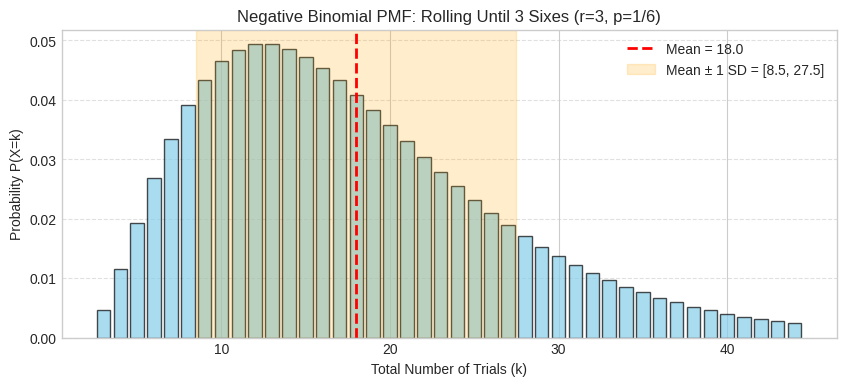
plt.title(f"Negative Binomial PMF: Rolling Until 3 Sixes (r={r_viz}, p=1/6)")
plt.xlabel("Total Number of Trials (k)")
plt.ylabel("Probability P(X=k)")
plt.legend(loc='upper right', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.savefig('ch07_negative_binomial_pmf_generic.svg', format='svg', bbox_inches='tight')
plt.show()
The PMF shows the distribution is centered around the expected value r/p = 3/(1/6) = 18 trials. You can see our calculated P(X=4) ≈ 0.0116 as a small bar near the left tail at k=4. The shaded region shows mean ± 1 standard deviation.
# Remove existing SVG if present
if os.path.exists('ch07_negative_binomial_cdf_generic.svg'):
os.remove('ch07_negative_binomial_cdf_generic.svg')
# Plotting the CDF
cdf_values_viz = nbinom_viz.cdf(k_values_viz - r_viz)
plt.figure(figsize=(10, 4))
plt.step(k_values_viz, cdf_values_viz, where='post', color='darkgreen', linewidth=2)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.1f}')
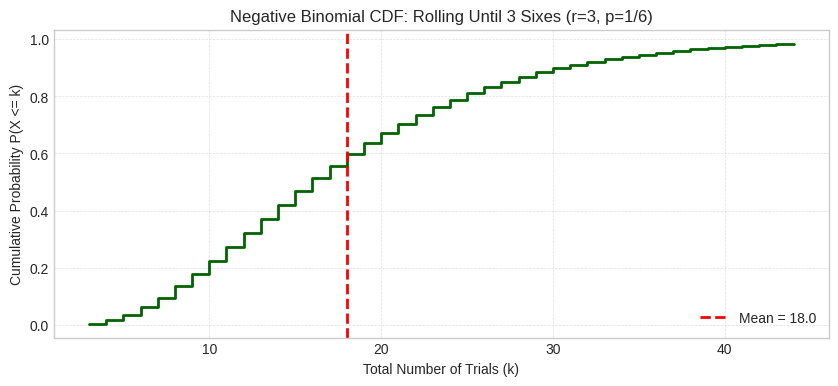
plt.title(f"Negative Binomial CDF: Rolling Until 3 Sixes (r={r_viz}, p=1/6)")
plt.xlabel("Total Number of Trials (k)")
plt.ylabel("Cumulative Probability P(X <= k)")
plt.legend(loc='lower right', fontsize=10)
plt.grid(True, which='both', linestyle='--', linewidth=0.5, alpha=0.6)
plt.savefig('ch07_negative_binomial_cdf_generic.svg', format='svg', bbox_inches='tight')
plt.show()
The CDF shows P(X ≤ k), the cumulative probability of getting 3 sixes within k rolls. At k=4, the CDF shows P(X ≤ 4) = P(X=3) + P(X=4) ≈ 0.0046 + 0.0116 ≈ 0.0162, which is the very low cumulative probability in the left tail. The red dashed line marks the mean (18 trials).
Quick Check Questions
You flip a fair coin until you get 5 Heads. What distribution models this and what are the parameters?
Answer
Negative Binomial with r = 5, p = 0.5 - Counting trials until getting r successes, each trial has p = 0.5.
For a Negative Binomial distribution with r = 4 and p = 0.5, what is the expected value (mean)?
Answer
E[X] = r/p = 4/0.5 = 8 - Expected number of trials to get 4 successes.
A basketball player practices free throws until making 10 successful shots. Each shot has a 70% success rate. Which distribution and why?
Answer
Negative Binomial with r = 10, p = 0.7 - We’re waiting for a fixed number of successes (r = 10), not just the first success. Each trial (shot) is independent with constant probability p = 0.7.
This is NOT Geometric because we need 10 successes, not just 1.
How is Negative Binomial related to Geometric distribution?
Answer
Geometric is a special case where r = 1 - Negative Binomial with r=1 is identical to Geometric.
Geometric: waiting for 1st success
Negative Binomial: waiting for r-th success (r ≥ 1)
For Negative Binomial, why is the variance r(1-p)/p²?
Answer
The variance r(1-p)/p² grows with both r and uncertainty:
Increases with r: Waiting for more successes means more trials and more variability
Increases as p decreases: Lower success probability means higher uncertainty in when you’ll reach r successes
For example:
r=1, p=0.5: Var = 1×0.5/0.25 = 2
r=5, p=0.5: Var = 5×0.5/0.25 = 10 (more variable with more successes needed)
r=5, p=0.2: Var = 5×0.8/0.04 = 100 (much more variable with low p!)
The Poisson distribution models the number of events occurring in a fixed interval of time or space when events happen independently at a constant average rate.
Concrete Example
You receive an average of 4 customer calls per hour. How many calls will you get in the next hour?
We model this with a random variable X:
X = the number of calls in one hour
X can take values 0, 1, 2, 3, ... (any non-negative integer)
Algorithm visualization: The following diagram visualizes the Poisson formula as competing forces, building intuition for why each component exists:
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import poisson
from scipy.special import factorial
import matplotlib.patches as mpatches
def create_poisson_visual(lam=4):
"""Poisson distribution visualization showing the 'forces' intuition"""
k_max = 9
k_vals = np.arange(k_max + 1)
# Calculate components - the three "forces"
numerator = np.power(lam, k_vals) # Driver
denominator = factorial(k_vals) # Brake
constant = np.exp(-lam) # Scaler
prob = poisson.pmf(k_vals, lam)
# Setup figure - optimized for mobile viewing
fig, ax = plt.subplots(figsize=(14, 9))
ax.axis('off')
ax.set_xlim(-0.5, 11.5)
ax.set_ylim(0, 10)
# Layout constants - narrower boxes
box_width = 0.95
box_height = 0.9
gap = 0.2
start_y = 6.5
# Title
ax.text((k_max * (box_width + gap))/2, 9.5,
f'Visualizing Poisson: The Three Forces ($\lambda = {lam}$)',
ha='center', fontsize=22, fontweight='bold', color='#333333')
ax.text((k_max * (box_width + gap))/2, 9.0,
f'Expected rate: {lam} events. Probability of exactly k events?',
ha='center', fontsize=15, color='#555555')
# Draw probability boxes for each k value
for i, k in enumerate(k_vals):
x = i * (box_width + gap)
# Color intensity based on probability
max_p = max(prob)
alpha = 0.1 + 0.8 * (prob[i] / max_p)
box_color = plt.cm.Blues(alpha)
# Rounded rectangle for each k
rect = mpatches.FancyBboxPatch((x, start_y), box_width, box_height,
boxstyle="round,pad=0.1",
facecolor=box_color, edgecolor='#2c3e50', linewidth=1.5)
ax.add_patch(rect)
# k label
center_x = x + box_width/2
center_y = start_y + box_height/2
ax.text(center_x, center_y, f'k={k}',
ha='center', va='center', fontsize=17, fontweight='bold',
color='black' if alpha < 0.6 else 'white')
# Formula and result below box - larger fonts, better spacing
calc_text = f"$\\frac{{{lam}^{{{k}}} \\cdot e^{{-{lam}}}}}{{{int(denominator[i])}}}$"
result_text = f"= {prob[i]:.4f}"
ax.text(center_x, start_y - 0.35, calc_text,
ha='center', va='top', fontsize=15, color='#333333')
ax.text(center_x, start_y - 1.05, result_text,
ha='center', va='top', fontsize=13, fontweight='bold', color='#333333')
# The Three Forces - Explanatory boxes with better positioning
# Force 1: The Driver (Numerator)
bbox_driver = dict(boxstyle="round,pad=0.5", fc="#fae5d3", ec="#d35400", lw=1.5)
ax.text(1.2, 3.3, "Force 1: The Driver\n(Numerator)\n\n" + r"$\lambda^k$" +
"\n\nPushes UP exponentially.\nHigher λ or k → more likely.",
ha='center', va='top', fontsize=12, bbox=bbox_driver, color='#873600')
# Force 2: The Brake (Denominator)
bbox_brake = dict(boxstyle="round,pad=0.5", fc="#d5f5e3", ec="#27ae60", lw=1.5)
ax.text(5.2, 3.3, "Force 2: The Brake\n(Denominator)\n\n" + r"$k!$" +
"\n\nPulls DOWN super-fast.\nEventually crushes\nthe numerator.",
ha='center', va='top', fontsize=12, bbox=bbox_brake, color='#145a32')
# Force 3: The Scaler (Constant)
bbox_scaler = dict(boxstyle="round,pad=0.5", fc="#ebf5fb", ec="#2980b9", lw=1.5)
ax.text(9.2, 3.3, "The Scaler\n(Constant)\n\n" + r"$e^{-\lambda}$" +
"\n\nFixed dampener.\nEnsures total = 1.",
ha='center', va='top', fontsize=12, bbox=bbox_scaler, color='#154360')
# Phase arrows showing growth and decay - adjusted for narrower boxes
# Growth phase
peak_k = int(lam)
if peak_k > 0 and peak_k * (box_width + gap) < 4.5 * (box_width + gap):
arrow_y = 4.8
ax.annotate("", xy=(peak_k * (box_width + gap), arrow_y), xytext=(0.3, arrow_y),
arrowprops=dict(arrowstyle="->", color="#d35400", lw=2.5))
ax.text(peak_k * (box_width + gap) / 2, arrow_y + 0.15, "Driver Wins (Growth)",
ha='center', va='bottom', color="#d35400", fontsize=11, fontweight='bold')
# Decay phase
if peak_k < k_max - 2:
arrow_y = 4.8
decay_start = max(peak_k + 1, 5) * (box_width + gap)
decay_end = 10.5
ax.annotate("", xy=(decay_end, arrow_y), xytext=(decay_start, arrow_y),
arrowprops=dict(arrowstyle="->", color="#27ae60", lw=2.5))
ax.text((decay_end + decay_start)/2, arrow_y + 0.15, "Brake Wins (Decay)",
ha='center', va='bottom', color="#27ae60", fontsize=11, fontweight='bold')
# Peak indicator - shorter arrow to avoid overlap with subtitle
peak_x = peak_k * (box_width + gap) + box_width/2
ax.annotate(f"Peak near k={peak_k}\n(Forces Balanced)",
xy=(peak_x, start_y + box_height),
xytext=(peak_x, start_y + box_height + 0.9),
arrowprops=dict(facecolor='black', shrink=0.05, width=1.5),
ha='center', fontsize=10, va='bottom')
# General Formula - centered properly for narrower layout
ax.text(5.2, 0.8, r"General Formula: $P(X=k) = \frac{\lambda^k e^{-\lambda}}{k!}$",
ha='center', fontsize=20,
bbox=dict(facecolor='white', edgecolor='black', boxstyle='round,pad=0.6', lw=2))
plt.tight_layout()
plt.show()
# Create the visualization with lambda = 4
create_poisson_visual(lam=4)
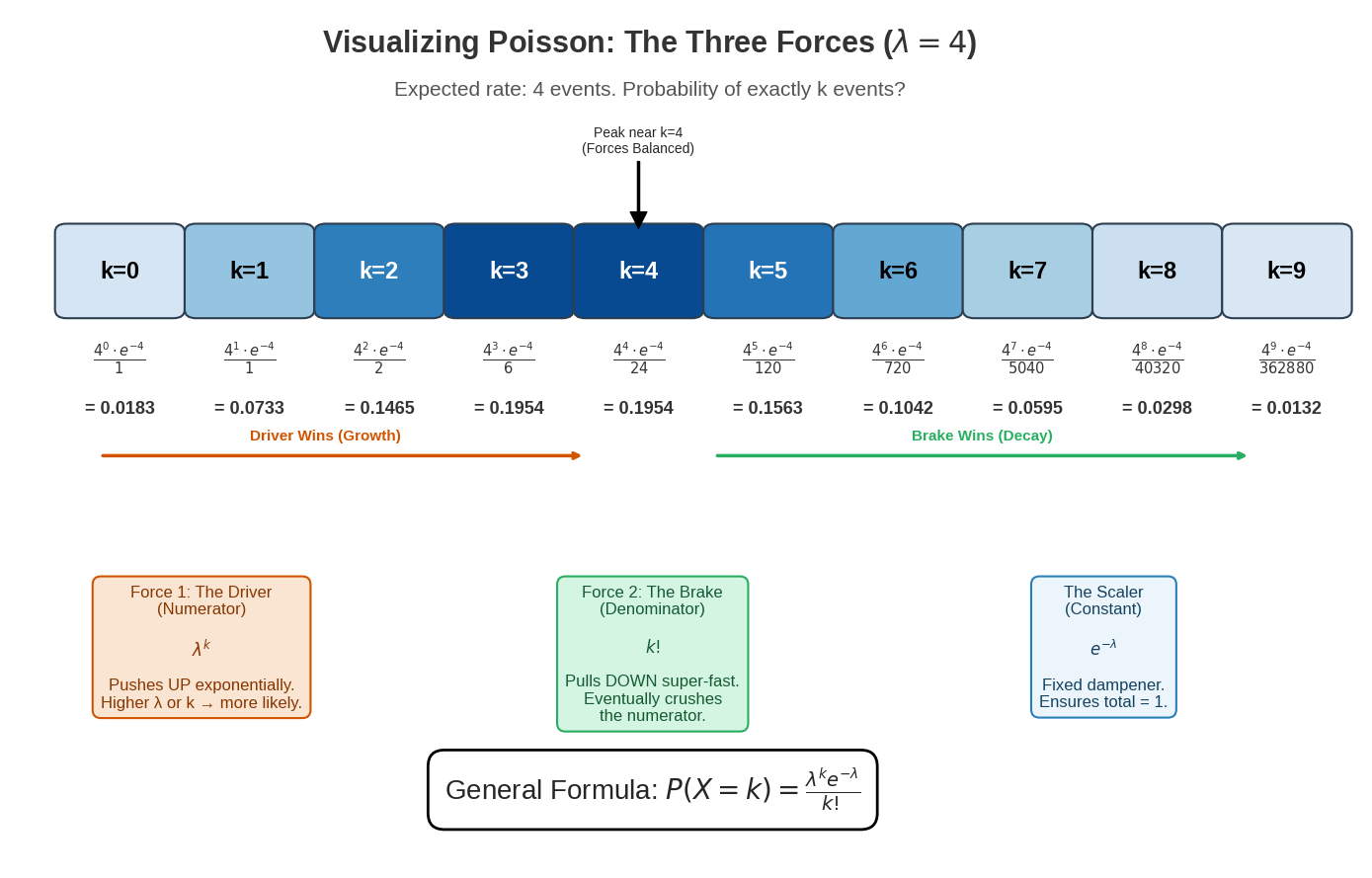
The diagram above visualizes the Poisson distribution (λ = 4) using a three forces metaphor that explains how each component of the formula P(X=k)=k!λke−λ shapes the probability distribution:
The Three Forces:
The Driver (Numerator: λk) — Shown in the orange box, this force pushes probabilities UP exponentially. As k increases, the numerator grows rapidly when λ is large. This represents the “raw likelihood” of k events based on the rate λ.
The Brake (Denominator: k!) — Shown in the green box, this force pulls probabilities DOWN super-exponentially. Factorial growth eventually crushes the numerator for large k values, causing the rapid decay in the right tail of the distribution.
The Scaler (Constant: e−λ) — Shown in the blue box, this is a fixed dampening factor that normalizes the distribution to ensure all probabilities sum to 1.
Reading the Diagram:
Color-coded boxes (k=0 through k=9): Darker blue indicates higher probability. Each box shows the formula and exact probability for that k value.
Orange arrow (“Driver Wins”): In the left portion (k < λ), the numerator grows faster than the denominator, causing probabilities to increase.
Green arrow (“Brake Wins”): In the right portion (k > λ), the factorial denominator overwhelms the numerator, causing probabilities to decay rapidly.
Peak indicator: Shows where the forces balance at k ≈ λ, marking the mode of the distribution. For λ = 4, the peak occurs at k = 4 with probability ≈ 0.195 (19.5%).
This “tug-of-war” between the driver and brake forces creates the characteristic bell-like shape of the Poisson distribution, with the peak occurring where these forces are balanced.
Key Characteristics
Scenarios: Emails per hour, customer arrivals per day, typos per page, emergency calls per shift, defects per unit area
Parameter: λ, average number of events in the interval (λ>0)
Random Variable: X∈{0,1,2,...}
Mean:E[X]=λ
Variance:Var(X)=λ
Standard Deviation:SD(X)=λ
Note: Mean and variance are equal in a Poisson distribution, so the standard deviation is simply the square root of λ.
Relationship to Other Distributions: The Poisson distribution is an approximation to the Binomial distribution when n is large, p is small, and λ=np is moderate. Rule of thumb: use Poisson approximation when n≥20 and p≤0.05.
Visualizing the Distribution
Let’s visualize a Poisson distribution with λ=4 (our call center example):
# Remove existing SVG if present
if os.path.exists('ch07_poisson_pmf_generic.svg'):
os.remove('ch07_poisson_pmf_generic.svg')
# Create Poisson distribution for visualization (λ=4)
lambda_viz = 4
poisson_viz = stats.poisson(mu=lambda_viz)
# Calculate mean and std
mean_viz = poisson_viz.mean()
std_viz = poisson_viz.std()
# Plotting the PMF
k_values_viz = np.arange(0, 15)
pmf_values_viz = poisson_viz.pmf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.bar(k_values_viz, pmf_values_viz, color='skyblue', edgecolor='black', alpha=0.7)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.1f}')
# Add mean ± 1 std region
plt.axvspan(mean_viz - std_viz, mean_viz + std_viz, alpha=0.2, color='orange',
label=f'Mean ± 1 SD = [{mean_viz - std_viz:.1f}, {mean_viz + std_viz:.1f}]')
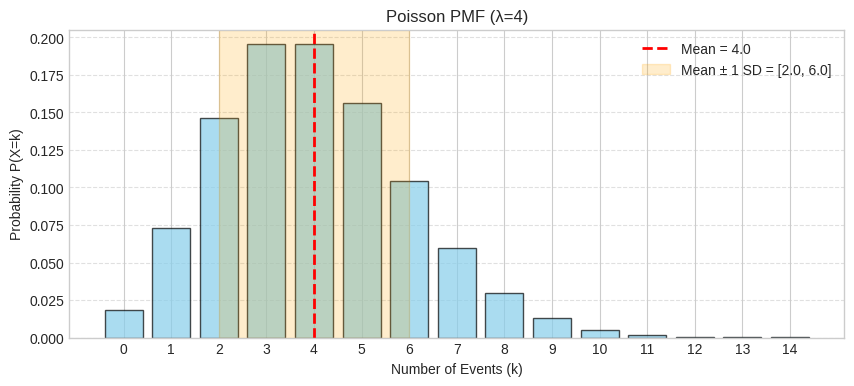
plt.title(f"Poisson PMF (λ={lambda_viz})")
plt.xlabel("Number of Events (k)")
plt.ylabel("Probability P(X=k)")
plt.xticks(k_values_viz)
plt.legend(loc='upper right', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.savefig('ch07_poisson_pmf_generic.svg', format='svg', bbox_inches='tight')
plt.show()
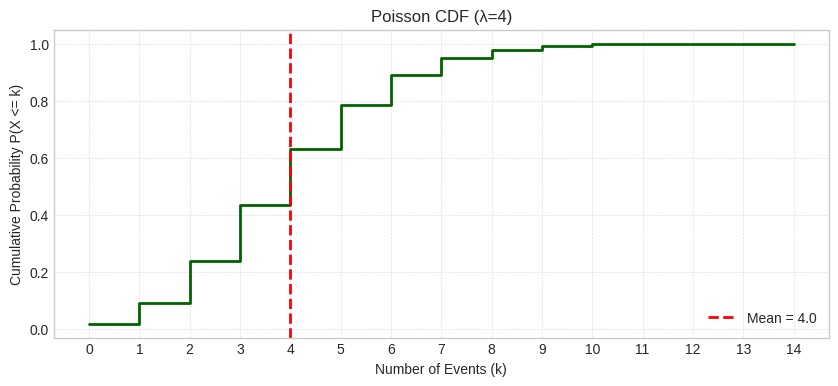
The PMF shows the distribution centered around λ = 4 with reasonable probability for nearby values. The shaded region shows mean ± 1 standard deviation (4=2).
# Remove existing SVG if present
if os.path.exists('ch07_poisson_cdf_generic.svg'):
os.remove('ch07_poisson_cdf_generic.svg')
# Plotting the CDF
cdf_values_viz = poisson_viz.cdf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.step(k_values_viz, cdf_values_viz, where='post', color='darkgreen', linewidth=2)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.1f}')
plt.title(f"Poisson CDF (λ={lambda_viz})")
plt.xlabel("Number of Events (k)")
plt.ylabel("Cumulative Probability P(X <= k)")
plt.xticks(k_values_viz)
plt.legend(loc='lower right', fontsize=10)
plt.grid(True, which='both', linestyle='--', linewidth=0.5, alpha=0.6)
plt.savefig('ch07_poisson_cdf_generic.svg', format='svg', bbox_inches='tight')
plt.show()
The CDF shows P(X ≤ k), useful for questions like “What’s the probability of 6 or fewer calls?” The red dashed line marks the mean.
Quick Check Questions
A call center receives an average of 12 calls per hour. What distribution models the number of calls in one hour and what is the parameter?
Answer
Poisson distribution with λ = 12 - Events occurring at a constant average rate in a fixed interval.
For a Poisson distribution with λ = 7, what are the mean and variance?
Answer
Mean = 7, Variance = 7 - For Poisson, both equal λ. This is a unique property of the Poisson distribution.
You count the number of typos on a random page of a book. The average is 2 typos per page. Which distribution?
Answer
Poisson with λ = 2 - Counting discrete events (typos) occurring in a fixed space (one page) at a constant average rate.
This fits Poisson’s requirements:
Events happen independently
Constant average rate
Counting occurrences in fixed interval/space
True or False: In a Poisson distribution, the mean can be different from the variance.
Answer
False - A key property of Poisson is that mean = variance = λ.
This property can help you identify when Poisson might not be the best fit. If your data has variance much larger or smaller than the mean, consider other distributions (e.g., Negative Binomial for overdispersion).
When can Poisson approximate Binomial?
Answer
When n is large, p is small, and np is moderate - Specifically:
n ≥ 20 and p ≤ 0.05, or
n ≥ 100 and np ≤ 10
Then Binomial(n, p) ≈ Poisson(λ = np)
Example: Binomial(n=1000, p=0.003) ≈ Poisson(λ=3)
This works because rare events in many trials behave like events occurring at a constant rate.
The Hypergeometric distribution models the number of successes in a sample drawn without replacement from a finite population. This is different from Binomial, which assumes sampling with replacement (or infinite population).
Concrete Example
You draw 5 cards from a standard deck of 52 cards. How many Aces will you get?
We model this with a random variable X:
X = the number of Aces in the 5-card hand
Population: N = 52 cards total
Successes in population: K = 4 Aces
Sample size: n = 5 cards drawn
X can take values 0, 1, 2, 3, 4 (can’t get more than 4 Aces!)
This is: (ways to choose k successes from K) × (ways to choose n-k failures from N-K) / (total ways to choose n items from N).
Key Characteristics
Scenarios: Cards from a deck, defective items in small batch, tagged fish in sample, jury selection from finite pool
Parameters:
N: total population size
K: total number of successes in population
n: sample size (n≤N)
Random Variable: X, bounded by max(0,n−(N−K))≤X≤min(n,K)
Mean:E[X]=nNK
Variance:Var(X)=nNK(1−NK)(N−1N−n)
Standard Deviation:SD(X)=nNK(1−NK)(N−1N−n)
The term N−1N−n is the finite population correction factor. As N→∞, this approaches 1, and Hypergeometric → Binomial with p=K/N.
Visualizing the Distribution
Let’s visualize a Hypergeometric distribution with N=52, K=4, n=5 (our card example):
# Remove existing SVG if present
if os.path.exists('ch07_hypergeometric_pmf_generic.svg'):
os.remove('ch07_hypergeometric_pmf_generic.svg')
# Create Hypergeometric distribution for visualization (N=52, K=4, n=5)
N_viz = 52
K_viz = 4
n_viz = 5
hypergeom_viz = stats.hypergeom(M=N_viz, n=K_viz, N=n_viz)
# Calculate mean and std
mean_viz = hypergeom_viz.mean()
std_viz = hypergeom_viz.std()
# Plotting the PMF
k_values_viz = np.arange(0, min(n_viz, K_viz) + 1)
pmf_values_viz = hypergeom_viz.pmf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.bar(k_values_viz, pmf_values_viz, color='skyblue', edgecolor='black', alpha=0.7)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.2f}')
# Add mean ± 1 std region
plt.axvspan(mean_viz - std_viz, mean_viz + std_viz, alpha=0.2, color='orange',
label=f'Mean ± 1 SD = [{mean_viz - std_viz:.2f}, {mean_viz + std_viz:.2f}]')
plt.title(f"Hypergeometric PMF (N={N_viz}, K={K_viz}, n={n_viz})")
plt.xlabel("Number of Successes in Sample (k)")
plt.ylabel("Probability P(X=k)")
plt.xticks(k_values_viz)
plt.legend(loc='upper right', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.savefig('ch07_hypergeometric_pmf_generic.svg', format='svg', bbox_inches='tight')
The PMF shows most likely to get 0 Aces (about 0.66 probability), less likely to get 1 or 2. The red dashed line marks the mean, and the orange shaded region shows mean ± 1 standard deviation.
# Remove existing SVG if present
if os.path.exists('ch07_hypergeometric_cdf_generic.svg'):
os.remove('ch07_hypergeometric_cdf_generic.svg')
# Plotting the CDF
cdf_values_viz = hypergeom_viz.cdf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.step(k_values_viz, cdf_values_viz, where='post', color='darkgreen', linewidth=2)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.2f}')
plt.title(f"Hypergeometric CDF (N={N_viz}, K={K_viz}, n={n_viz})")
plt.xlabel("Number of Successes in Sample (k)")
plt.ylabel("Cumulative Probability P(X <= k)")
plt.xticks(k_values_viz)
plt.legend(loc='lower right', fontsize=10)
plt.grid(True, which='both', linestyle='--', linewidth=0.5, alpha=0.6)
plt.savefig('ch07_hypergeometric_cdf_generic.svg', format='svg', bbox_inches='tight')
The CDF shows P(X ≤ k), useful for questions like “What’s the probability of getting at most 1 Ace?” The red dashed line marks the mean.
Quick Check Questions
You draw 7 cards from a deck of 52. You want to know how many hearts you get. What distribution models this and what are the parameters?
Answer
Hypergeometric with N=52, K=13, n=7 - Sampling without replacement from a finite population (13 hearts in 52 cards).
For a Hypergeometric distribution with N=50, K=10, n=5, what is the expected value (mean)?
Answer
E[X] = n(K/N) = 5 × (10/50) = 1 - Expected number of successes in the sample.
A quality inspector randomly selects 10 products from a batch of 100 (where 15 are defective) without replacement. Which distribution?
Answer
Hypergeometric with N=100, K=15, n=10 - Sampling without replacement from a finite population.
This is NOT Binomial because:
We’re sampling without replacement
The sample size (10) is significant relative to population (100)
Each draw changes the probability for subsequent draws
What’s the key difference between Binomial and Hypergeometric distributions?
Answer
Hypergeometric samples WITHOUT replacement (finite population), while Binomial samples WITH replacement (or assumes infinite population).
Key implications:
Hypergeometric: Trials are NOT independent (each draw affects the next)
Binomial: Trials ARE independent (constant probability p)
Rule of thumb: If N > 20n, Hypergeometric ≈ Binomial because the sample is small relative to the population.
When can Hypergeometric be approximated by Binomial?
Answer
When the population is much larger than the sample - Specifically, when N > 20n.
In this case, Hypergeometric(N, K, n) ≈ Binomial(n, p=K/N)
Example: Drawing 10 cards from a population of 1000 cards. The small sample barely affects the population proportions, so with/without replacement gives nearly identical results.
Scenarios: Fair die roll, random selection from a list, lottery number selection, random password digit
Parameters:
a: minimum value (integer)
b: maximum value (integer, b≥a)
Random Variable: X∈{a,a+1,…,b}
Mean:E[X]=2a+b
Variance:Var(X)=12(b−a+1)2−1
Standard Deviation:SD(X)=12(b−a+1)2−1
Relationship to Other Distributions: The Discrete Uniform distribution is a special case of the Categorical distribution where all k categories have equal probability pi=1/k. If outcomes aren’t equally likely, use Categorical instead.
Visualizing the Distribution
Let’s visualize a Discrete Uniform distribution for a fair die (a=1, b=6):
# Remove existing SVG if present
if os.path.exists('ch07_discrete_uniform_pmf.svg'):
os.remove('ch07_discrete_uniform_pmf.svg')
# Create Discrete Uniform distribution for visualization (fair die)
a_viz = 1
b_viz = 6
from scipy.stats import randint
# scipy.stats.randint uses [low, high) so we add 1 to b
uniform_viz = randint(low=a_viz, high=b_viz+1)
# Calculate mean and std
mean_viz = uniform_viz.mean()
std_viz = uniform_viz.std()
# Plotting the PMF
k_values_viz = np.arange(a_viz, b_viz+1)
pmf_values_viz = uniform_viz.pmf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.bar(k_values_viz, pmf_values_viz, color='skyblue', edgecolor='black', alpha=0.7)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.2f}')
# Add mean ± 1 std region
plt.axvspan(mean_viz - std_viz, mean_viz + std_viz, alpha=0.2, color='orange',
label=f'Mean ± 1 SD = [{mean_viz - std_viz:.2f}, {mean_viz + std_viz:.2f}]')
plt.title(f"Discrete Uniform PMF (a={a_viz}, b={b_viz})")
plt.xlabel("Outcome")
plt.ylabel("Probability")
plt.ylim(0, 0.25)
plt.xticks(k_values_viz)
plt.legend(loc='upper right', fontsize=10)
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.savefig('ch07_discrete_uniform_pmf.svg', format='svg', bbox_inches='tight')
The PMF shows six equal bars, each with probability 1/6, representing the fair die. The shaded region shows mean ± 1 standard deviation.
# Remove existing SVG if present
if os.path.exists('ch07_discrete_uniform_cdf.svg'):
os.remove('ch07_discrete_uniform_cdf.svg')
# Plotting the CDF
cdf_values_viz = uniform_viz.cdf(k_values_viz)
plt.figure(figsize=(10, 4))
plt.step(k_values_viz, cdf_values_viz, where='post', color='darkgreen', linewidth=2)
# Add mean line
plt.axvline(mean_viz, color='red', linestyle='--', linewidth=2, label=f'Mean = {mean_viz:.2f}')
plt.title(f"Discrete Uniform CDF (a={a_viz}, b={b_viz})")
plt.xlabel("Outcome")
plt.ylabel("Cumulative Probability P(X <= k)")
plt.ylim(0, 1.1)
plt.xticks(k_values_viz)
plt.legend(loc='lower right', fontsize=10)
plt.grid(True, which='both', linestyle='--', linewidth=0.5, alpha=0.6)
plt.savefig('ch07_discrete_uniform_cdf.svg', format='svg', bbox_inches='tight')
The CDF increases in equal steps of 1/6 at each value, reaching 1.0 at the maximum value. The red dashed line marks the mean.
Quick Check Questions
You randomly select a card from a standard deck (52 cards). If X represents the card number (1-13, where 1=Ace, 11=Jack, 12=Queen, 13=King), what distribution models this and what are the parameters?
Answer
Discrete Uniform distribution with a = 1, b = 13 - Each card number is equally likely (4 of each in the deck).
For a Discrete Uniform distribution with a = 5 and b = 15, what is the probability of getting exactly 10?
Answer
P(X = 10) = 1/(15-5+1) = 1/11 ≈ 0.091 - All values in the range are equally likely.
What is the mean of a Discrete Uniform distribution on the integers from 1 to 100?
Answer
Mean = (1+100)/2 = 50.5 - The mean is the midpoint of the range.
You’re modeling the outcome of rolling a fair six-sided die. Should you use Discrete Uniform or Categorical distribution?
Answer
Discrete Uniform distribution - Since it’s a fair die, all outcomes (1-6) are equally likely with probability 1/6 each.
Use Discrete Uniform(a=1, b=6).
Note: If the die were loaded (unequal probabilities), you’d use the Categorical distribution instead.
For a Discrete Uniform distribution on integers from a to b, why is the variance equal to 12(b−a)(b−a+2)?
Answer
The variance formula reflects how spread out the values are:
Larger range (b-a): Higher variance - values are more spread out
Formula intuition: The variance grows with the square of the range, similar to continuous uniform distributions
The Categorical distribution models a single trial with multiple possible outcomes (more than 2), where each outcome has its own probability. It’s the generalization of the Bernoulli distribution to more than two categories.
Concrete Example
Suppose you’re rolling a loaded six-sided die where the faces have different probabilities:
Face 1: probability 0.1
Face 2: probability 0.15
Face 3: probability 0.20
Face 4: probability 0.25
Face 5: probability 0.20
Face 6: probability 0.10
We model this with a random variable X:
X = the face that appears
X can take values in {1,2,3,4,5,6}
Each value has its own probability: P(X=1)=0.1,P(X=2)=0.15, etc.
The Categorical PMF
For a Categorical distribution with k possible outcomes and probabilities p1,p2,…,pk where ∑i=1kpi=1:
Scenarios: Loaded die, customer choosing from menu categories, survey response (multiple choice), weather outcome (sunny/cloudy/rainy/snowy)
Parameters:
k: number of categories
p1,p2,…,pk: probabilities for each category (must sum to 1)
Random Variable: X∈{1,2,…,k}
Mean:E[X]=∑i=1ki⋅pi (weighted average of outcomes)
Variance:Var(X)=∑i=1ki2⋅pi−(∑i=1ki⋅pi)2
Relationship to Other Distributions: Categorical generalizes Bernoulli (when k=2) and is a special case of Discrete Uniform (when all pi are equal). For multiple trials, use the Multinomial distribution instead.
Visualizing the Distribution
Let’s visualize our loaded die Categorical distribution:
The CDF increases by different amounts at each value, reflecting the varying probabilities.
Quick Check Questions
A traffic light can be red (50%), yellow (10%), or green (40%). What distribution models the color when you arrive at an intersection?
Answer
Categorical distribution with k=3 categories and probabilities p₁=0.5, p₂=0.1, p₃=0.4 - Single trial with three possible outcomes.
For a Categorical distribution with 4 equally likely outcomes, what is P(X = 2)?
Answer
P(X = 2) = 0.25 - For equally likely outcomes, each has probability 1/4.
How is the Categorical distribution related to the Bernoulli distribution?
Answer
Bernoulli is a special case of Categorical with k=2 - When there are only two categories, Categorical reduces to Bernoulli.
Categorical generalizes Bernoulli from 2 outcomes to k outcomes.
You’re observing a single customer’s choice from a menu with 5 items having probabilities [0.3, 0.25, 0.2, 0.15, 0.1]. Should you use Categorical or Multinomial distribution?
Answer
Categorical distribution - You’re observing a single trial (one customer making one choice).
Key distinction:
Categorical: Single trial, multiple outcomes (this scenario)
Multinomial: Multiple trials, counting how many times each outcome occurs
If you observed 100 customers and counted how many chose each item, that would be Multinomial.
When can you model a Categorical distribution as a Discrete Uniform distribution?
Answer
When all k categories have equal probability - If p₁ = p₂ = ... = pₖ = 1/k.
Example:
Rolling a fair die (6 equally likely outcomes): Can use either Categorical(p=[1/6, 1/6, 1/6, 1/6, 1/6, 1/6]) or Discrete Uniform(a=1, b=6)
Rolling a loaded die (unequal probabilities): Must use Categorical
Discrete Uniform is just a special case of Categorical where all probabilities are equal.
The Multinomial distribution models performing a fixed number of independent trials where each trial has multiple possible outcomes (more than 2), and we count how many times each outcome occurs. It’s the generalization of the Binomial distribution to more than two categories.
Concrete Example
Suppose you roll a fair six-sided die 20 times. We want to know how many times each face (1, 2, 3, 4, 5, 6) appears.
We model this with a random vector X=(X1,X2,X3,X4,X5,X6) where:
X1 = number of times face 1 appears
X2 = number of times face 2 appears
... and so on
Constraint: X1+X2+X3+X4+X5+X6=20
The probabilities for a fair die are:
p1=p2=p3=p4=p5=p6=61
The Multinomial PMF
For n independent trials with k possible outcomes and probabilities p1,p2,…,pk where ∑i=1kpi=1:
Scenarios: Rolling a die n times (counting each face), survey with multiple choice options, customer purchases across product categories, DNA base frequencies in a sequence
Parameters:
n: number of trials
k: number of categories
p1,p2,…,pk: probabilities for each category (must sum to 1)
Random Variables: X1,X2,…,Xk where Xi = count for category i, and ∑i=1kXi=n
Mean for each category:E[Xi]=npi
Variance for each category:Var(Xi)=npi(1−pi)
Relationship to Other Distributions: Multinomial generalizes Binomial (when k=2) and Categorical (single trial becomes multiple trials). Each individual category count Xi follows a Binomial distribution with parameters (n,pi).
Visualizing the Distribution
Multinomial distributions are challenging to visualize since they involve multiple variables. Let’s look at a simple case with k=3 categories:
# Remove existing SVG if present
if os.path.exists('ch07_multinomial_marginal.svg'):
os.remove('ch07_multinomial_marginal.svg')
# Simulate multinomial: rolling a 3-sided die 15 times
n_trials = 15
probs_3 = np.array([1/3, 1/3, 1/3])
# Generate many samples
n_sims = 10000
samples = np.random.multinomial(n_trials, probs_3, size=n_sims)
# Plot distribution of outcomes for Category 1 (marginal distribution)
category_1_counts = samples[:, 0]
plt.figure(figsize=(8, 3.5))
plt.hist(category_1_counts, bins=np.arange(0, n_trials+2)-0.5, density=True,
color='skyblue', edgecolor='black', alpha=0.7)
plt.title(f"Marginal Distribution of Category 1\n(Multinomial with n={n_trials}, k=3, all p=1/3)")
plt.xlabel("Count for Category 1")
plt.ylabel("Probability")
plt.xticks(range(0, n_trials+1))
plt.grid(axis='y', linestyle='--', alpha=0.6)
plt.savefig('ch07_multinomial_marginal.svg', format='svg', bbox_inches='tight')
The marginal distribution of any single category in a Multinomial distribution is actually a Binomial distribution! Here, Category 1 follows Binomial(n=15, p=1/3).
Connecting to our die example: We simplified to 3 categories for easier visualization, but the same principle applies to our 6-sided die example (n=20 rolls). Each face count would follow Binomial(n=20, p=1/6). The histogram would be similar but centered around 20/6 ≈ 3.33 instead of 15/3 = 5.
Quick Check Questions
You flip a fair coin 30 times and count heads and tails. What distribution models the counts?
Answer
Multinomial distribution with n=30, k=2, and p₁=p₂=0.5 - Or equivalently, Binomial(n=30, p=0.5) for the number of heads, since there are only 2 categories.
When k=2, Multinomial is the same as Binomial.
For a Multinomial distribution with n=100 trials and k=4 equally likely categories, what is the expected count for any one category?
Answer
E[X_i] = n × p_i = 100 × 0.25 = 25 - Each category is expected to appear 25 times.
Since all 4 categories are equally likely, p_i = 1/4 = 0.25 for each.
How is the Multinomial distribution related to the Binomial distribution?
Answer
Binomial is a special case of Multinomial with k=2 - When there are only two categories, Multinomial reduces to Binomial.
Multinomial generalizes Binomial from 2 outcomes to k outcomes across multiple trials.
You roll a die 100 times and count how many times each face (1-6) appears. Should you use Categorical or Multinomial distribution?
Answer
Multinomial distribution - You’re performing multiple trials (100 rolls) and counting how many times each outcome occurs.
Key distinction:
Categorical: Single trial, multiple possible outcomes (one roll)
Multinomial: Multiple trials, counting occurrences of each outcome (100 rolls)
Use Multinomial(n=100, k=6, p=[1/6, 1/6, 1/6, 1/6, 1/6, 1/6]) for a fair die.
In a Multinomial distribution, what is the relationship between the individual category counts X₁, X₂, ..., Xₖ?
Answer
They must sum to n - The constraint is: X₁ + X₂ + ... + Xₖ = n
This is because every trial must result in exactly one category, so the total count across all categories equals the number of trials.
Important implication: The counts are not independent - if you know k-1 of the counts, you can determine the last one.
Example: If n=100 and you know X₁=30, X₂=25, X₃=20 in a k=4 category case, then X₄ must equal 25 (since 30+25+20+25=100).
Understanding the connections between these distributions can deepen insight and provide useful approximations.
Bernoulli as a special case of Binomial: A Binomial distribution with n=1 trial (Binomial(1,p)) is equivalent to a Bernoulli distribution (Bernoulli(p)).
Geometric as a special case of Negative Binomial: A Negative Binomial distribution modeling the number of trials until the first success (r=1) (NegativeBinomial(1,p)) is equivalent to a Geometric distribution (Geometric(p)).
Binomial Approximation to Hypergeometric: If the population size N is much larger than the sample size n (e.g., N>20n), then drawing without replacement (Hypergeometric) is very similar to drawing with replacement. In this case, the Hypergeometric(N,K,n) distribution can be well-approximated by the Binomial(n,p=K/N) distribution. The finite population correction factor N−1N−n approaches 1.
Poisson Approximation to Binomial: If the number of trials n in a Binomial distribution is large, and the success probability p is small, such that the mean λ=np is moderate, then the Binomial(n,p) distribution can be well-approximated by the Poisson(λ=np) distribution. This is useful because the Poisson PMF is often easier to compute than the Binomial PMF when n is large. A common rule of thumb is to use this approximation if n≥20 and p≤0.05, or n≥100 and np≤10.
Example: Poisson approximation to Binomial
Consider Binomial(n=1000,p=0.005). Here n is large, p is small. The mean is λ=np=1000×0.005=5. We can approximate this with Poisson(λ=5).
Let’s compare the PMF values of both distributions to see how well the Poisson approximation works in practice.
The chart compares the Binomial(100, 0.03) distribution (blue bars) with the Poisson(3.0) approximation (red bars). The distributions are nearly identical, demonstrating that when n is large and p is small, the Poisson provides an excellent and computationally simpler approximation to the Binomial.
Categorical as generalization of Bernoulli: A Categorical distribution with k=2 categories (Categorical(p1,p2) where p1+p2=1) is equivalent to a Bernoulli distribution (Bernoulli(p1)). Categorical extends Bernoulli to handle more than two outcomes in a single trial.
Multinomial as generalization of Binomial: A Multinomial distribution with k=2 categories (Multinomial(n,p1,p2) where p1+p2=1) is equivalent to a Binomial distribution (Binomial(n,p1)). Multinomial extends Binomial to count outcomes across more than two categories.
Discrete Uniform as special case of Categorical: A Categorical distribution where all k probabilities are equal (p1=p2=⋯=pk=k1) is a Discrete Uniform distribution on k values. This represents maximum uncertainty about a single trial’s outcome.
Marginal distributions of Multinomial are Binomial: If (X1,X2,…,Xk)∼Multinomial(n,p1,p2,…,pk), then each individual count Xi follows a Binomial distribution: Xi∼Binomial(n,pi). This makes sense because we’re just counting successes (category i) vs. failures (all other categories) across n trials.
In this chapter, we explored nine fundamental discrete probability distributions:
Bernoulli: Single trial, two outcomes (Success/Failure).
Binomial: Fixed number of independent trials, counts successes.
Geometric: Number of trials until the first success.
Negative Binomial: Number of trials until a fixed number (r) of successes.
Poisson: Number of events in a fixed interval of time/space, given an average rate.
Hypergeometric: Number of successes in a sample drawn without replacement from a finite population.
Discrete Uniform: Single trial where all outcomes are equally likely.
Categorical: Single trial with multiple possible outcomes, each with its own probability.
Multinomial: Fixed number of trials with multiple possible outcomes, counting occurrences of each outcome.
We learned the scenarios each distribution models, their parameters, PMFs, means, and variances. Critically, we saw how to leverage scipy.stats functions (pmf, cdf, rvs, mean, var, std, sf) to perform calculations, generate simulations, and visualize these distributions. We also discussed important relationships, such as:
Mastering these distributions provides a powerful toolkit for modeling various random phenomena encountered in data analysis, science, engineering, and business. In the next chapters, we will transition to continuous random variables and their corresponding common distributions.
Decision Tree: Choosing the Right Distribution
Use this decision tree to help identify which distribution fits your scenario:
Key Questions to Ask:
How many trials? Single → Bernoulli/Categorical/Discrete Uniform. Fixed number → Binomial/Multinomial/Hypergeometric. Variable → Geometric/Negative Binomial.
How many outcomes per trial? Two → Bernoulli/Binomial/Geometric/Negative Binomial. More than two → Categorical/Multinomial/Discrete Uniform.
With or without replacement? With replacement (or infinite population) → Binomial. Without replacement (finite population) → Hypergeometric.
What are you counting? Successes in fixed trials → Binomial/Multinomial. Trials until success → Geometric/Negative Binomial. Events in interval → Poisson.
Are probabilities equal? Yes → Discrete Uniform. No → Categorical.
Example Applications:
“Flip a coin once” → Bernoulli (single trial, 2 outcomes)
“Flip a coin 10 times, count heads” → Binomial (fixed trials, 2 outcomes, with replacement)
“Roll a die until you get a 6” → Geometric (variable trials, waiting for first success)
“Draw 5 cards from a deck, count hearts” → Hypergeometric (fixed trials, 2 outcomes, without replacement)
“Count customers arriving per hour” → Poisson (events in interval)
“Roll a die once” → Discrete Uniform (single trial, 6 equally likely outcomes)
“Traffic light color when you arrive” → Categorical (single trial, 3 outcomes with different probabilities)
“Roll a die 20 times, count each face” → Multinomial (fixed trials, 6 outcomes)
While this chapter covers nine fundamental discrete distributions, many other distributions exist for specialized scenarios. Here’s how to learn about distributions beyond this chapter:
How to Approach Learning a New Distribution:
When you encounter a new distribution, follow these steps:
Understand the Scenario: What real-world process does it model? What makes it different from distributions you already know?
Identify the Parameters: What values define the distribution? (like n and p for Binomial, λ for Poisson)
Study the PMF (or PDF for continuous): How are probabilities calculated? What’s the formula?
PMF = Probability Mass Function (discrete distributions, like those in this chapter)
PDF = Probability Density Function (continuous distributions, covered in Chapters 8-9)
Learn Key Properties: What are the mean and variance? Are there special characteristics?
Explore Relationships: How does it relate to distributions you already know? Is it a special case or generalization of something familiar?
See Examples: Find concrete examples and visualizations to build intuition.
Practice with Code: Use scipy.stats or similar libraries to work with the distribution hands-on.
Key Resources for Learning About Other Distributions:
Wikipedia - Each distribution has a comprehensive article with a standardized format:
Definition and scenario
Parameters and support (possible values)
PMF formula (discrete) or PDF formula (continuous)
Customer Arrivals: The average number of customers arriving at a small cafe is 10 per hour. Assume arrivals follow a Poisson distribution.
a. What is the probability that exactly 8 customers arrive in a given hour?
b. What is the probability that 12 or fewer customers arrive in a given hour?
c. What is the probability that more than 15 customers arrive in a given hour?
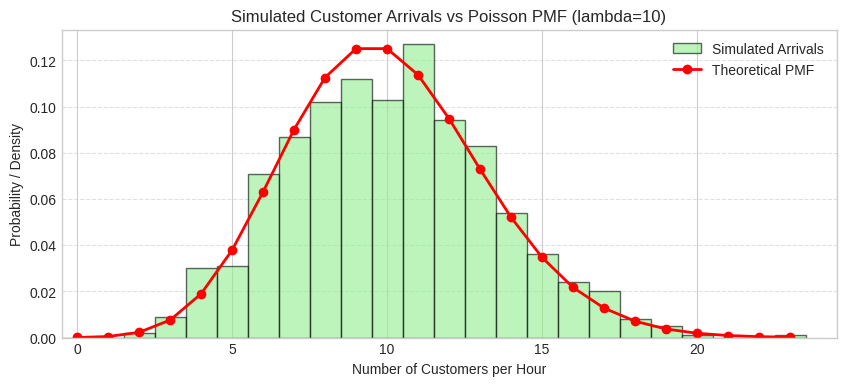
d. Simulate 1000 hours of customer arrivals and plot a histogram of the results. Compare it to the theoretical PMF.
Answer
a) Using the Poisson distribution with λ=10:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
lambda_cafe = 10
cafe_rv = stats.poisson(mu=lambda_cafe)
prob_8 = cafe_rv.pmf(8)
print(f"P(Exactly 8 customers) = {prob_8:.4f}")
P(Exactly 8 customers) = 0.1126
b) The probability of 12 or fewer customers:
prob_12_or_fewer = cafe_rv.cdf(12)
print(f"P(12 or fewer customers) = {prob_12_or_fewer:.4f}")
P(12 or fewer customers) = 0.7916
c) The probability of more than 15 customers:
prob_over_15 = cafe_rv.sf(15)
print(f"P(More than 15 customers) = {prob_over_15:.4f}")
The histogram closely matches the theoretical PMF, confirming the Poisson model.
Quality Control: A batch contains 50 items, of which 5 are defective. You randomly sample 8 items without replacement.
a. What distribution models the number of defective items in your sample? State the parameters.
b. What is the probability that exactly 1 item in your sample is defective?
c. What is the probability that at most 2 items in your sample are defective?
d. What is the expected number of defective items in your sample?
Answer
a) This follows a Hypergeometric distribution since we’re sampling without replacement from a finite population. The parameters are: N=50 (population size), K=5 (defective items in population), n=8 (sample size).
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
N_qc = 50
K_qc = 5
n_qc = 8
qc_rv = stats.hypergeom(M=N_qc, n=K_qc, N=n_qc)
print(f"Distribution: Hypergeometric(N={N_qc}, K={K_qc}, n={n_qc})")
Distribution: Hypergeometric(N=50, K=5, n=8)
b) Probability of exactly 1 defective item:
prob_1_defective = qc_rv.pmf(1)
print(f"P(Exactly 1 defective in sample) = {prob_1_defective:.4f}")
P(Exactly 1 defective in sample) = 0.4226
c) Probability of at most 2 defective items:
prob_at_most_2 = qc_rv.cdf(2)
print(f"P(At most 2 defectives in sample) = {prob_at_most_2:.4f}")
P(At most 2 defectives in sample) = 0.9758
d) Expected number of defective items:
expected_defective = qc_rv.mean()
print(f"Expected number of defectives in sample = {expected_defective:.4f}")
# Theoretical: E[X] = n * (K/N) = 8 * (5/50) = 0.8
Expected number of defectives in sample = 0.8000
Website Success: A new website feature has a 3% chance of being used by a visitor (p=0.03). Assume visitors are independent.
a. If 100 visitors come to the site, what is the probability that exactly 3 visitors use the feature? What distribution applies?
b. What is the probability that 5 or fewer visitors use the feature out of 100?
c. What is the expected number of users out of 100 visitors?
d. A developer tests the feature repeatedly until the first user successfully uses it. What is the probability that the first success occurs on the 20th visitor? What distribution applies?
e. What is the expected number of visitors needed to see the first success?
f. How many visitors are expected until the 5th user is observed? What distribution applies?
Answer
a) This follows a Binomial distribution with n=100 trials and p=0.03: