NN01 - Edge Detection Intuition: A Single Neuron as Pattern Matching
A hands-on guide to understanding how a single neuron detects patterns in images
Have you ever wondered how neural networks can recognize faces, read handwriting, or detect objects in photos? It all starts with something surprisingly simple: pattern matching.
In this post, we’ll build an edge detector from scratch to understand the fundamental operation at the heart of all neural networks. By the end, you’ll have an intuitive grasp of:
How a single neuron works (it’s just multiplication and addition!)
Why weights determine what patterns a neuron responds to
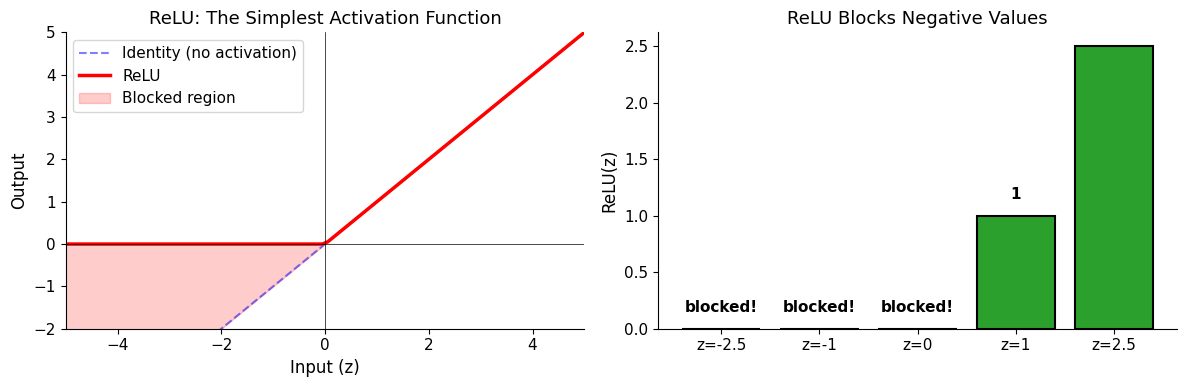
How ReLU activation acts as a gate
Why bias matters for controlling sensitivity
No prior deep learning knowledge required — just basic math intuition.
That’s it! The magic is in what values the weights take — they determine what pattern the neuron responds to.
Intuition: Think of each input as an expert’s opinion, and the weights as how much you trust each expert. A large positive weight means “this input is very important.” A negative weight means “if this input is high, I’m less interested.”
It acts as a gate: positive signals pass through unchanged, negative signals get blocked.
Why is this useful? Without an activation function, stacking layers would be pointless — the whole network would collapse into a single linear transformation. ReLU introduces non-linearity, which allows the network to learn complex patterns.
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
x = np.linspace(-5, 5, 100)
y_relu = np.maximum(0, x)
axes[0].plot(x, x, 'b--', alpha=0.5, label='Identity (no activation)')
axes[0].plot(x, y_relu, 'r-', linewidth=2.5, label='ReLU')
axes[0].axhline(y=0, color='black', linewidth=0.5)
axes[0].axvline(x=0, color='black', linewidth=0.5)
axes[0].fill_between(x[x<0], 0, x[x<0], alpha=0.2, color='red', label='Blocked region')
axes[0].set_xlabel('Input (z)', fontsize=12)
axes[0].set_ylabel('Output', fontsize=12)
axes[0].set_title('ReLU: The Simplest Activation Function', fontsize=13)
axes[0].legend()
axes[0].set_xlim(-5, 5)
axes[0].set_ylim(-2, 5)
sample_z = [-2.5, -1, 0, 1, 2.5]
sample_relu = [max(0, z) for z in sample_z]
colors = ['#d62728' if z <= 0 else '#2ca02c' for z in sample_z]
axes[1].bar(range(len(sample_z)), sample_relu, color=colors, edgecolor='black', linewidth=1.5)
axes[1].set_xticks(range(len(sample_z)))
axes[1].set_xticklabels([f'z={z}' for z in sample_z])
axes[1].set_ylabel('ReLU(z)', fontsize=12)
axes[1].set_title('ReLU Blocks Negative Values', fontsize=13)
for i, (z, out) in enumerate(zip(sample_z, sample_relu)):
label = f'{out}' if out > 0 else 'blocked!'
axes[1].annotate(label, (i, out + 0.15), ha='center', fontsize=11, fontweight='bold')
plt.tight_layout()
plt.show()
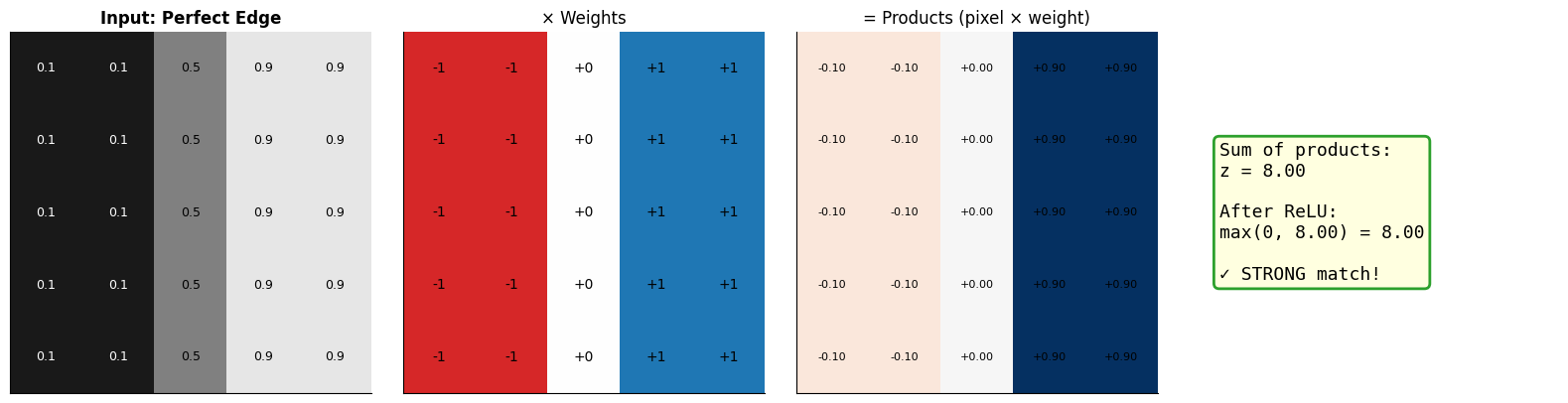
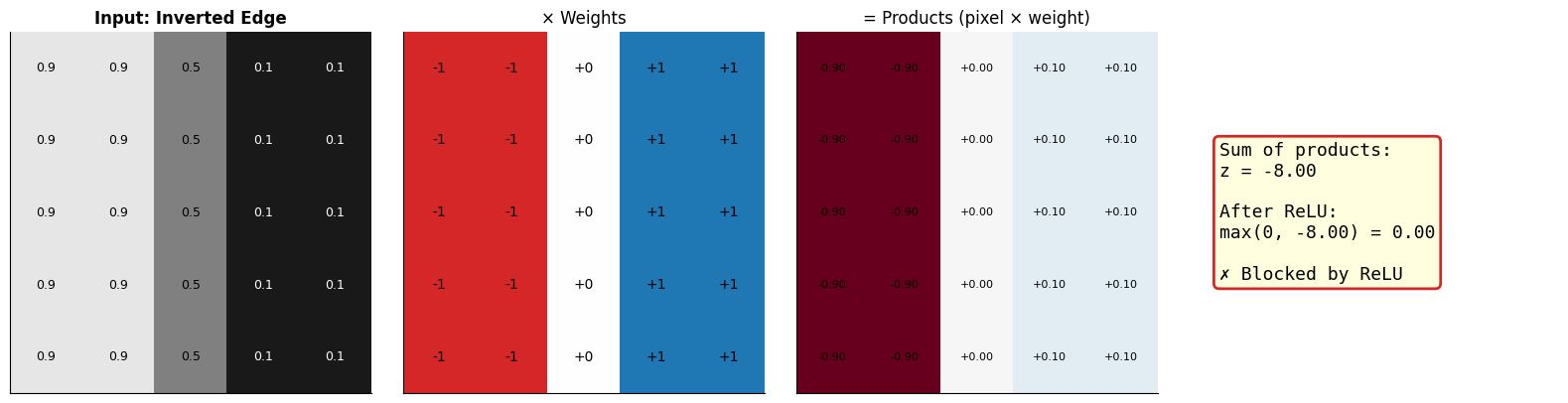
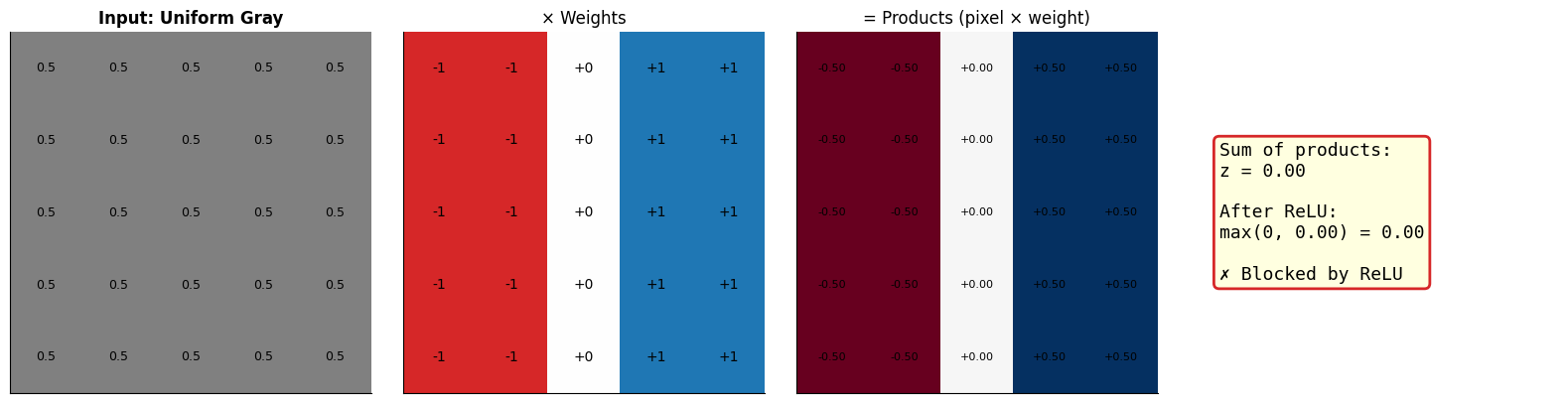
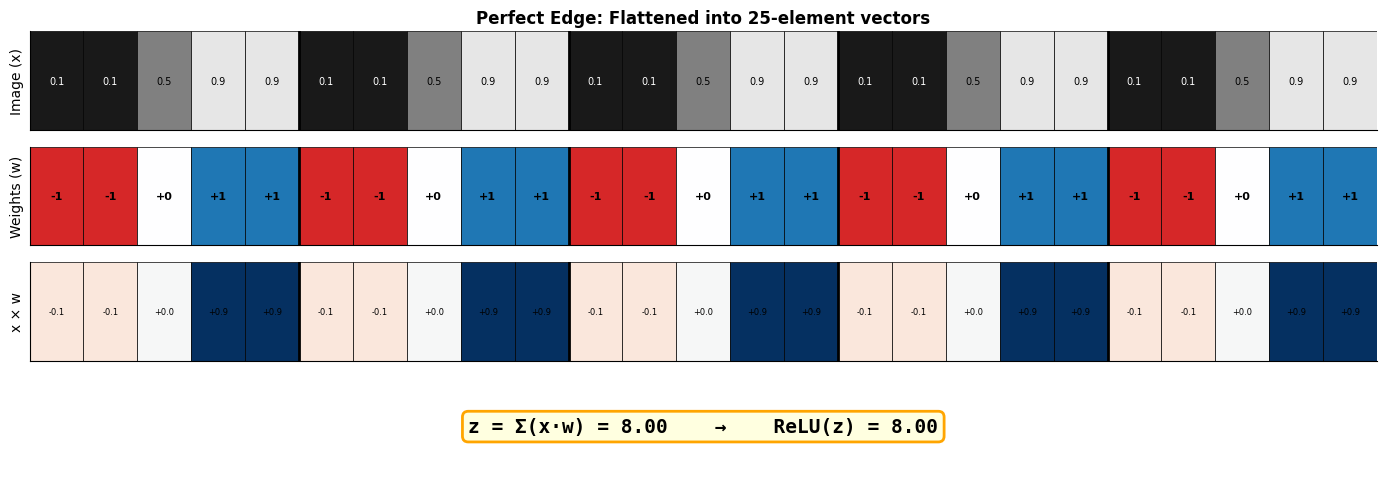
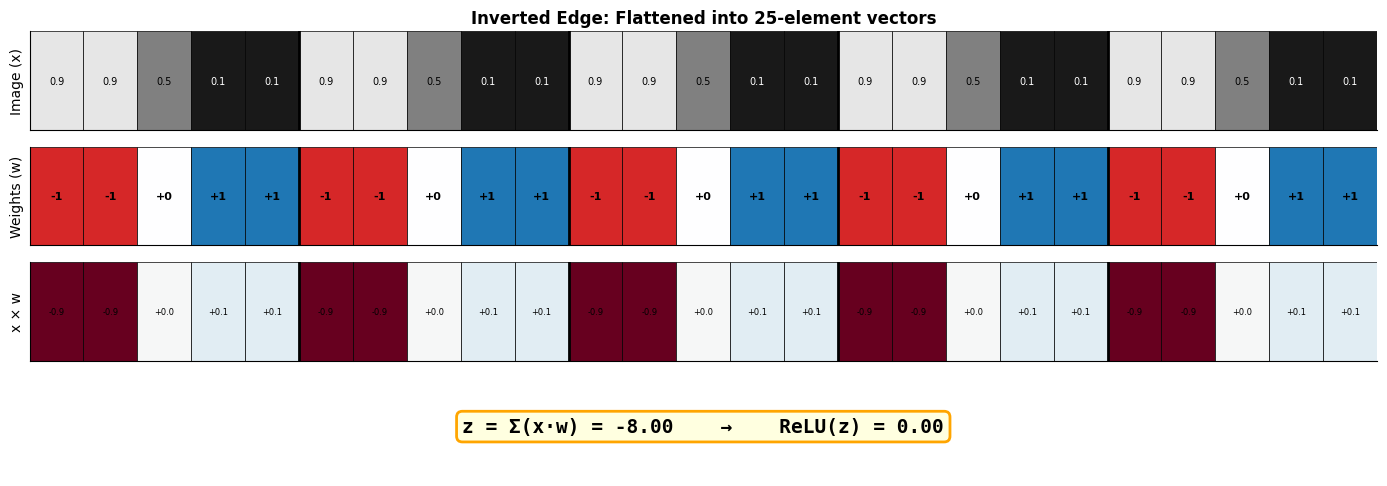
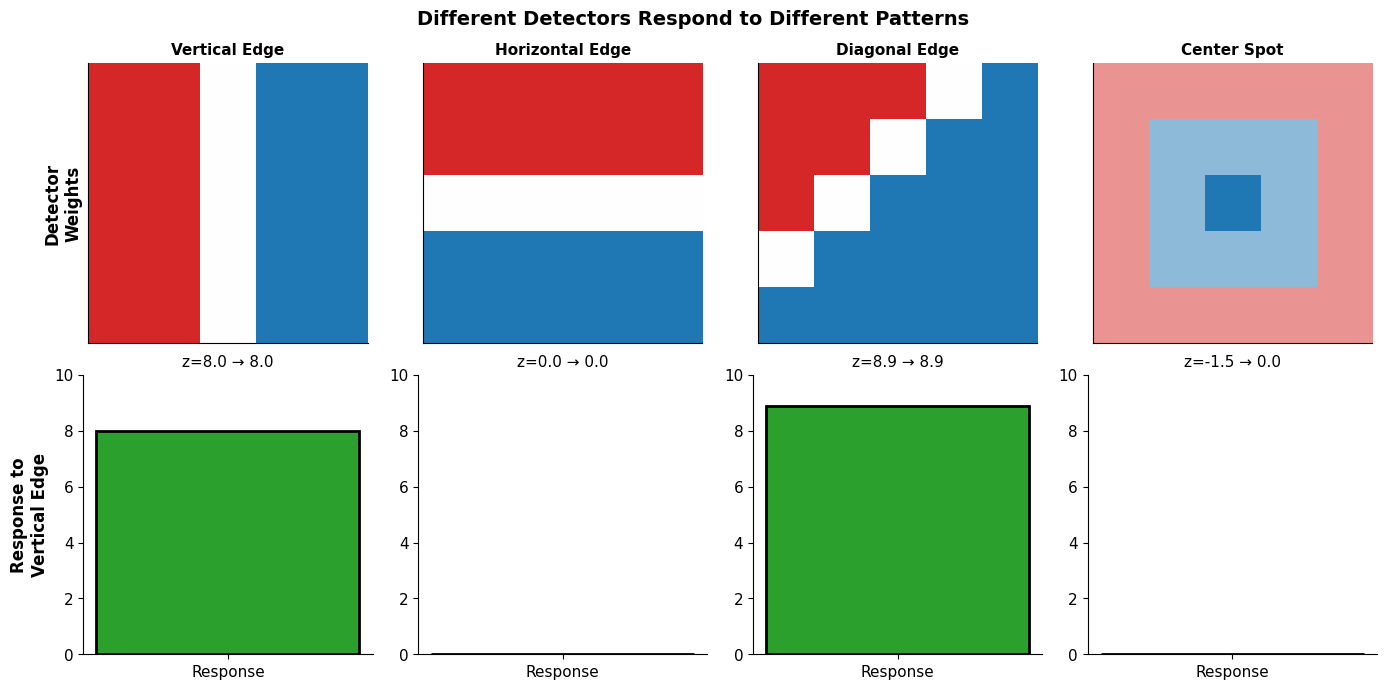
To detect a vertical edge (dark on left, bright on right), we set:
Negative weights (-1) on the left columns → “I want darkness here”
Positive weights (+1) on the right columns → “I want brightness here”
Zero weights (0) in the middle → “I don’t care about this region”
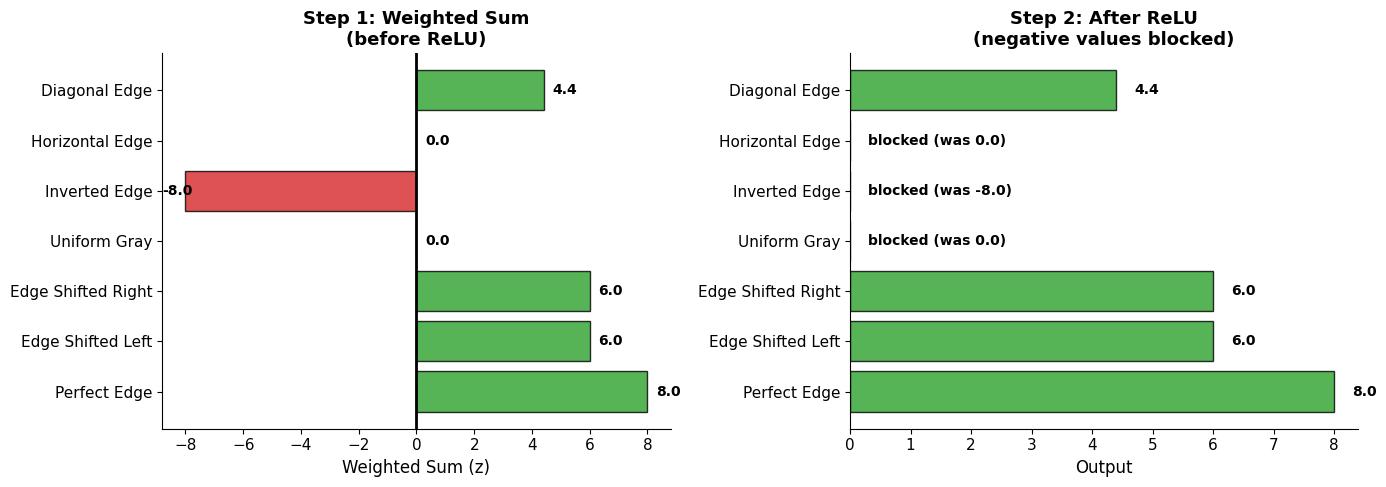
When an image with this exact pattern arrives, the positive and negative contributions reinforce each other, giving a high score. When the pattern doesn’t match, contributions cancel out or go negative.
# The key insight: these weights define WHAT the neuron looks for
edge_weights = np.array([
[-1, -1, 0, +1, +1],
[-1, -1, 0, +1, +1],
[-1, -1, 0, +1, +1],
[-1, -1, 0, +1, +1],
[-1, -1, 0, +1, +1]
], dtype=float)
fig, ax = plt.subplots(figsize=(7, 6))
cmap = LinearSegmentedColormap.from_list('edge', ['#d62728', 'white', '#1f77b4'])
im = ax.imshow(edge_weights, cmap=cmap, vmin=-1, vmax=1)
for i in range(5):
for j in range(5):
ax.text(j, i, f'{edge_weights[i, j]:+.0f}', ha='center', va='center', fontsize=16, fontweight='bold')
ax.set_xticks(range(5))
ax.set_yticks(range(5))
ax.set_title('Vertical Edge Detector Weights\n(Red = -1 "want dark", Blue = +1 "want bright")', fontsize=13)
plt.colorbar(im, ax=ax, label='Weight Value', shrink=0.8)
plt.tight_layout()
plt.show()
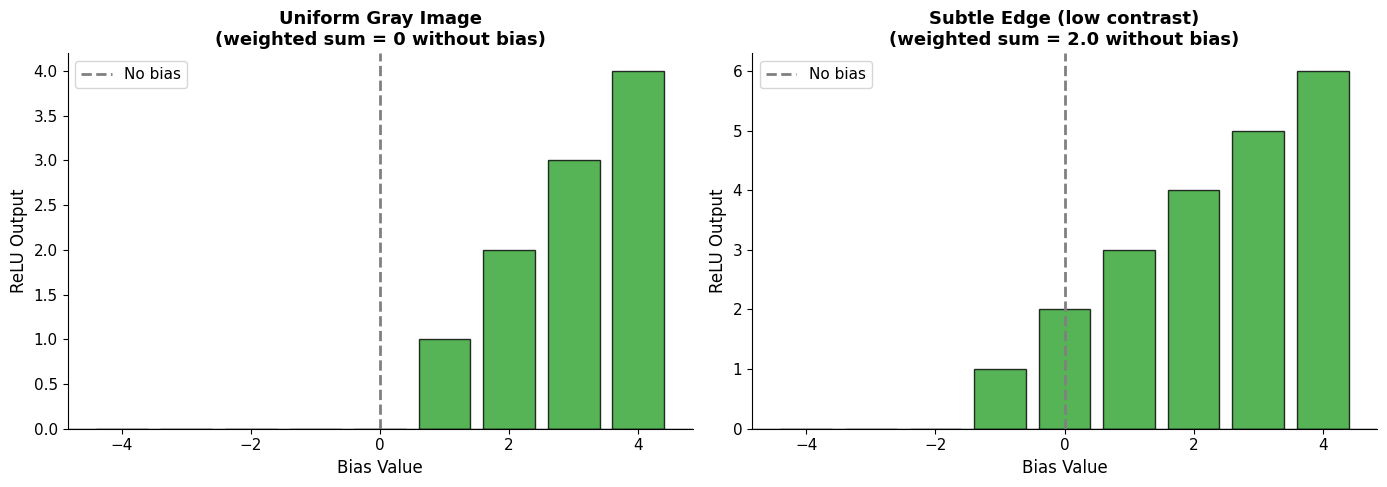
Note: We’re setting bias b=0 for now to keep things simple. This lets us focus purely on how the weight pattern matches the input. We’ll explore bias later!
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
names = [r['name'] for r in results]
weighted_sums = [r['weighted_sum'] for r in results]
relu_outputs = [r['relu_output'] for r in results]
colors_ws = ['#2ca02c' if ws > 0 else '#d62728' for ws in weighted_sums]
axes[0].barh(names, weighted_sums, color=colors_ws, alpha=0.8, edgecolor='black')
axes[0].axvline(x=0, color='black', linewidth=2)
axes[0].set_xlabel('Weighted Sum (z)', fontsize=12)
axes[0].set_title('Step 1: Weighted Sum\n(before ReLU)', fontsize=13, fontweight='bold')
for i, v in enumerate(weighted_sums):
axes[0].text(v + (0.3 if v >= 0 else -0.8), i, f'{v:.1f}', va='center', fontsize=10, fontweight='bold')
colors_relu = ['#2ca02c' if o > 0 else '#999999' for o in relu_outputs]
axes[1].barh(names, relu_outputs, color=colors_relu, alpha=0.8, edgecolor='black')
axes[1].set_xlabel('Output', fontsize=12)
axes[1].set_title('Step 2: After ReLU\n(negative values blocked)', fontsize=13, fontweight='bold')
for i, (v, ws) in enumerate(zip(relu_outputs, weighted_sums)):
label = f'{v:.1f}' if v > 0 else f'blocked (was {ws:.1f})'
axes[1].text(v + 0.3, i, label, va='center', fontsize=10, fontweight='bold')
plt.tight_layout()
plt.show()
Layer 3 neurons combine shapes into parts (eyes, wheels, windows)
Output layer combines parts into final classifications (cat, car, digit)
This hierarchy — from simple to complex — is why deep learning works so well. And it all starts with the simple pattern matching we’ve explored here!
The key insight: We don’t design these weights by hand. During training, the network automatically discovers what patterns are useful for the task. Backpropagation adjusts each weight to reduce errors, and useful detectors emerge naturally.
A neuron is a pattern matcher. High output = good match, zero output = poor match.
Weights encode knowledge. The specific values determine what the neuron “looks for.”
Learning = finding good weights. Training adjusts weights until useful patterns emerge.
Depth creates hierarchy. Simple detectors combine into complex recognizers.
This simple mechanism — multiply, sum, activate — repeated billions of times with learned weights, is how neural networks learn to see, read, translate, and even generate art.
Now you understand the atom of deep learning. Everything else is scale and clever architecture!