Why one brain is good, but eight brains are better.
In L03 - Self-Attention, we built the “Search Engine” of the Transformer. We learned how the word “it” can look up the word “animal” to resolve ambiguity.
But there is a limitation. A single self-attention layer acts like a single pair of eyes. It can focus on one aspect of the sentence at a time. Consider the sentence:
The chicken didn’t cross the road because it was too wide.
To understand this fully, the model needs to do two things simultaneously:
Syntactic Analysis: Link “it” to the subject “road” (because roads are wide).
Semantic Analysis: Understand that “wide” is a physical property preventing crossing.
If we only have one attention head, the model has to average these different relationships into a single vector. It muddies the waters.
Multi-Head Attention solves this by giving the model multiple “heads” (independent attention mechanisms) that run in parallel.
By the end of this post, you’ll understand:
The intuition of the “Committee of Experts.”
Why we project vectors into different Subspaces.
How to implement the tensor reshaping magic (
viewandtranspose) in PyTorch.
Part 1: The Intuition (The Committee)¶
The Committee Metaphor¶
Think of the embedding dimension () as a massive report containing everything we know about a word.
If we ask a single person to read that report and summarize “grammar,” “tone,” “tense,” and “meaning” all at once, they might miss details.
Instead, we hire a Committee of 8 Experts:
Head 1 (The Linguist): Only looks for Subject-Verb agreement.
Head 2 (The Historian): Looks for past/present tense consistency.
Head 3 (The Translator): Looks for definitions and synonyms.
...
In the Transformer, we don’t just copy the input 8 times. We project the input into 8 different lower-dimensional spaces. This allows each head to specialize.
Visualizing Multi-Head Projection¶
Let’s visualize this head specialization. In the plot below:
The Input (Mixed Info): The large multi-colored bar represents the full word embedding ().
The Projection: We project this into 8 equal-sized subspaces ().
The Result: Each head gets a vector that is 1/8th the size of the original, containing only the specific info it needs.

We draw 3 heads for readability—imagine 8 in the real model.
Parameter Implications: Why Reduced Dimensions?¶
Let’s look at the parameter implications of using reduced dimensions (64) per head instead of full dimensions (512):
# Parameter-count intuition: "full 512 per head" vs "reduced dims per head (8×64)"
d_model = 512
h = 8
d_k = d_model // h # Each head gets 64 dimensions instead of 512
# Scenario A: Each head gets full 512-dim projections (wasteful)
# Would need 8 separate (512×512) matrices for EACH of Q, K, V (3 matrices total)
params_if_full = 3 * h * (d_model * d_model) # 3 = Q, K, V
# Scenario B: Each head gets 64-dim projections (efficient)
# Need 8 × (512×64) matrices for EACH of Q, K, V (3 matrices total)
params_reduced = 3 * h * (d_model * d_k) # 3 = Q, K, V
# Scenario C: One big matrix (actual implementation)
# Single (512×512) matrix for EACH of Q, K, V (3 matrices total)
# THEN reshape the 512-dim output into 8 heads × 64 dims (the "split" operation)
params_actual = 3 * (d_model * d_model) # 3 = Q, K, V
print(f"d_model={d_model}, heads={h}, d_k={d_k}")
print("QKV parameters:")
print(f" if full dims: {params_if_full:,}")
print(f" if reduced dims: {params_reduced:,}")
print(f" actual (1 big W): {params_actual:,}")
print(f" reduced == actual? {params_reduced == params_actual}")
print()
print("Note: Scenario C has the SAME param count as single-head attention,")
print("but the difference is in the OUTPUT: we reshape it into 8 heads × 64 dims")d_model=512, heads=8, d_k=64
QKV parameters:
if full dims: 6,291,456
if reduced dims: 786,432
actual (1 big W): 786,432
reduced == actual? True
Note: Scenario C has the SAME param count as single-head attention,
but the difference is in the OUTPUT: we reshape it into 8 heads × 64 dims
The code above shows that using reduced dimensions per head keeps parameters constant (786K vs 6.3M for full dimensions per head). But why do this instead of giving each head the full 512 dimensions?
Forced specialization. With only 64 dimensions, each head must be selective about what it captures, encouraging distinct patterns:
Head 1 might focus on syntax (subject-verb agreement)
Head 2 might focus on semantics (word meaning relationships)
Head 3 might focus on positional patterns (nearby vs distant dependencies)
Think of it like hiring specialists with limited notepads. If each expert had unlimited space, they might all write the same general report. But with only 64 dimensions, each head is forced to focus on what matters most to its specialized role.
How Heads Learn Their Roles¶
When we say “Head 1 (The Linguist)” we’re using a metaphor for intuition. In reality:
You only specify
num_heads=8in your codeThe model learns what each head should focus on during training through backpropagation
The “roles” are emergent - they’re patterns discovered by gradient descent, not programmed by you
Descriptive, not prescriptive - Labels like “Linguist” are what researchers assign after analyzing what a trained model learned
You can’t tell the model “Head 1, you focus on grammar!” - it discovers its own patterns that minimize loss. Different training runs or datasets might result in different specializations.
Part 2: The Multi-Head Pipeline¶
Now that we understand the “why” (Specialization), let’s look at the “how” (The Pipeline).
The Multi-Head Attention mechanism isn’t a single black box; it is a specific sequence of operations. It allows the model to process information in parallel and then synthesize the results.
Let’s start with the big picture:
The 4-Step Process¶
Linear Projections (Mix, then Split): We don’t just use the raw input. We multiply the input by specific weight matrices () for each head. This creates the specialized “subspaces” we saw in Part 1.
Independent Attention: Each head runs the standard Scaled Dot-Product Attention independently.
Concatenation: Stitch the head outputs back together along the feature dimension.
Final Linear (Another Mix): Apply one last learned linear layer () to blend the heads into a single unified vector.
The Key Insight: Mix, Then Split¶
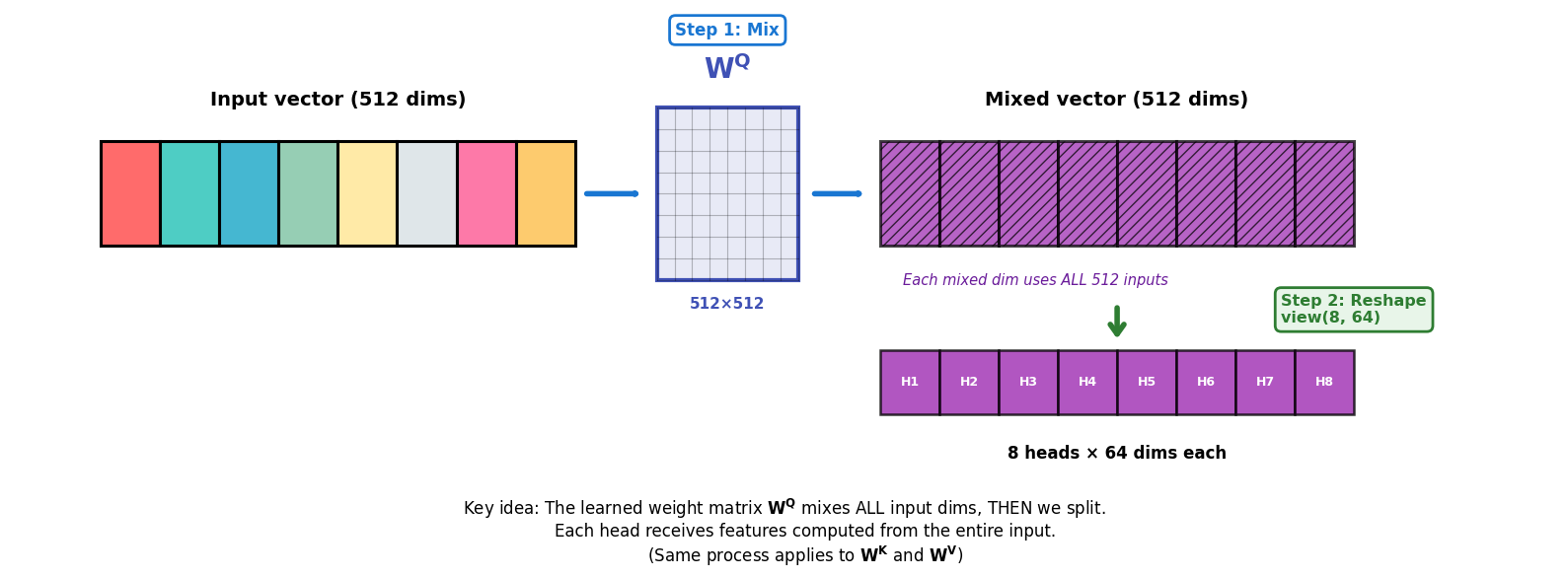
Now let’s zoom into Step 1, which is the operation most people misinterpret.
It’s tempting to think multi-head attention “just splits the 512 dims into 8 chunks.” That’s not what happens.
Instead, the split happens in two stages:
Mix (learned linear layer): We first apply a learned matrix (, , ). When you compute , each of the 512 output dimensions is a weighted sum of ALL 512 input dimensions. This means the network can learn to combine any input features together before splitting into heads.
Split (reshape/view): Only after that mix do we reshape the resulting 512-dimensional output into 8 heads × 64 dims.
Why does this matter? During training, the network can learn such that:
Output dimensions 0-63 (Head 1’s slice) contain features useful for syntax
Output dimensions 64-127 (Head 2’s slice) contain features useful for semantics
And so on...
This is what enables head specialization—each head gets features specifically curated for its role, not just a random slice of the input.
Keep this invariant in mind: the split step only works when is divisible by so that . If you change any of these values in the code, recompute
d_k = D // Hfirst.
# Concrete example: Prove that each output dimension mixes ALL input dimensions
torch.manual_seed(1)
D = 8 # Small example for clarity
x0 = torch.randn(D) # One token vector [D]
W = torch.randn(D, D) # Mix matrix (like W^Q, W^K, or W^V) [D×D]
q0 = x0 @ W # Matrix multiply: [D] @ [D×D] = [D]
print("=" * 60)
print("DEMONSTRATING THE MIX OPERATION")
print("=" * 60)
print(f"\nInput vector x0 (shape {x0.shape}):")
print(x0)
print(f"\nMix matrix W (shape {W.shape}):")
print(W)
print(f"\nOutput vector q0 = x0 @ W (shape {q0.shape}):")
print(q0)
# Proof: Pick any output dimension (let's use index 3) and show it depends on ALL inputs
output_idx = 3
print(f"\n--- Verifying q0[{output_idx}] uses ALL input dimensions ---")
print(f"q0[{output_idx}] = {q0[output_idx].item():.4f}")
print()
# Show the column of W that produces this output dimension
print(f"W[:, {output_idx}] (weights for output dimension {output_idx}):")
print(W[:, output_idx])
print()
# Manual computation: q0[j] = dot product of x0 with column j of W
manual = (x0 * W[:, output_idx]).sum() # x0[0]*W[0,3] + x0[1]*W[1,3] + ... + x0[7]*W[7,3]
print(f"Manual calculation: sum of (x0[i] * W[i,{output_idx}]) for ALL i from 0 to {D-1}")
print(f" = {manual.item():.4f}")
print()
print(f"✓ Matches! This proves q0[{output_idx}] is a weighted combination of")
print(f" ALL {D} input dimensions, not just one chunk.")
print("=" * 60)============================================================
DEMONSTRATING THE MIX OPERATION
============================================================
Input vector x0 (shape torch.Size([8])):
tensor([ 0.6614, 0.2669, 0.0617, 0.6213, -0.4519, -0.1661, -1.5228, 0.3817])
Mix matrix W (shape torch.Size([8, 8])):
tensor([[-0.6970, -1.1608, 0.6995, 0.1991, 0.8657, 0.2444, -0.6629, 0.8073],
[ 1.1017, -0.1759, -2.2456, -1.4465, 0.0612, -0.6177, -0.7981, -0.1316],
[ 1.8793, -0.0721, 0.1578, -0.7735, 0.1991, 0.0457, 0.1530, -0.4757],
[-0.1110, 0.2927, -0.1578, -0.0288, 2.3571, -1.0373, 1.5748, -0.6298],
[-0.9274, 0.5451, 0.0663, -0.4370, 0.7626, 0.4415, 1.1651, 2.0154],
[ 0.1374, 0.9386, -0.1860, -0.6446, 1.5392, -0.8696, -3.3312, -0.7479],
[-0.0255, -1.0233, -0.5962, -1.0055, -0.2106, -0.0075, 1.6734, 0.0103],
[-0.7040, -0.1853, -0.9962, -0.8313, -0.4610, -0.5601, 0.3956, -0.9823]])
Output vector q0 = x0 @ W (shape torch.Size([8])):
tensor([ 0.0465, 0.4481, 0.3035, 1.1985, 1.6100, -0.9023, -2.0339, -1.0991])
--- Verifying q0[3] uses ALL input dimensions ---
q0[3] = 1.1985
W[:, 3] (weights for output dimension 3):
tensor([ 0.1991, -1.4465, -0.7735, -0.0288, -0.4370, -0.6446, -1.0055, -0.8313])
Manual calculation: sum of (x0[i] * W[i,3]) for ALL i from 0 to 7
= 1.1985
✓ Matches! This proves q0[3] is a weighted combination of
ALL 8 input dimensions, not just one chunk.
============================================================
Let’s visualize that “Mix → Split” distinction (shown for , but and work identically):
Now let’s see the complete 4-step pipeline in action:
# A minimal 4-step pipeline on tiny shapes with DETAILED OUTPUT
import math
import torch
import torch.nn as nn
B, S, D, H = 2, 4, 8, 2
x = torch.randn(B, S, D)
def split_heads(t, H):
B, S, D = t.shape
d_k = D // H
return t.view(B, S, H, d_k).transpose(1, 2) # [B,H,S,d_k]
def merge_heads(t):
B, H, S, d_k = t.shape
return t.transpose(1, 2).contiguous().view(B, S, H * d_k) # [B,S,D]
def scaled_dot_attn(qh, kh, vh):
# qh,kh,vh: [B,H,S,d_k]
scores = qh @ kh.transpose(-2, -1) / math.sqrt(qh.shape[-1]) # [B,H,S,S]
attn = torch.softmax(scores, dim=-1)
out = attn @ vh # [B,H,S,d_k]
return out, attn
print("=" * 70)
print("MULTI-HEAD ATTENTION: 4-STEP PIPELINE")
print("=" * 70)
print(f"→ Starting with input")
print(f" x: {x.shape} (Batch={B}, Seq={S}, D={D})")
print()
print(f"Using {H} heads, each with d_k={D//H} dimensions")
print()
# Step 1: linear projections (Mix)
print("Step 1: LINEAR PROJECTIONS (Mix)")
print("-" * 70)
Wq = torch.randn(D, D)
Wk = torch.randn(D, D)
Wv = torch.randn(D, D)
Wo = torch.randn(D, D)
q = x @ Wq
k = x @ Wk
v = x @ Wv
print(f" Q = x @ W_q: {q.shape}")
print(f" K = x @ W_k: {k.shape}")
print(f" V = x @ W_v: {v.shape}")
print(" ✓ Each projection mixes ALL D input dimensions")
print()
# Step 1 continued: Split
print("Step 1b: SPLIT INTO HEADS")
print("-" * 70)
qh = split_heads(q, H)
kh = split_heads(k, H)
vh = split_heads(v, H)
print(f" After split: {qh.shape} = [B, H, S, d_k]")
print(f" ✓ Now we have {H} independent attention mechanisms in parallel")
print()
# Step 2: independent attention (in parallel)
print("Step 2: SCALED DOT-PRODUCT ATTENTION (Per Head)")
print("-" * 70)
out_h, attn = scaled_dot_attn(qh, kh, vh)
print(f" Attention weights: {attn.shape} = [B, H, S, S]")
print(f" Head outputs: {out_h.shape} = [B, H, S, d_k]")
print(f" ✓ Each of {H} heads computed attention independently")
print()
# Show attention weights for first batch, first head
print(f" Example: Attention weights from batch 0, head 0:")
print(f" {attn[0, 0]}")
print()
# Step 3: concat
print("Step 3: CONCATENATE HEADS")
print("-" * 70)
concat = merge_heads(out_h)
print(f" Before concat: {out_h.shape} = [B, H, S, d_k]")
print(f" After concat: {concat.shape} = [B, S, D]")
print(f" ✓ Merged {H} × {D//H} = {D} dimensions back together")
print()
# Step 4: final mix
print("Step 4: FINAL OUTPUT PROJECTION")
print("-" * 70)
y = concat @ Wo
print(f" Final output: {y.shape} = [B, S, D]")
print(f" ✓ One more learned mixing to combine head perspectives")
print()
print("=" * 70)
print("✓ COMPLETE: Input [B,S,D] → Output [B,S,D]")
print("=" * 70)======================================================================
MULTI-HEAD ATTENTION: 4-STEP PIPELINE
======================================================================
→ Starting with input
x: torch.Size([2, 4, 8]) (Batch=2, Seq=4, D=8)
Using 2 heads, each with d_k=4 dimensions
Step 1: LINEAR PROJECTIONS (Mix)
----------------------------------------------------------------------
Q = x @ W_q: torch.Size([2, 4, 8])
K = x @ W_k: torch.Size([2, 4, 8])
V = x @ W_v: torch.Size([2, 4, 8])
✓ Each projection mixes ALL D input dimensions
Step 1b: SPLIT INTO HEADS
----------------------------------------------------------------------
After split: torch.Size([2, 2, 4, 4]) = [B, H, S, d_k]
✓ Now we have 2 independent attention mechanisms in parallel
Step 2: SCALED DOT-PRODUCT ATTENTION (Per Head)
----------------------------------------------------------------------
Attention weights: torch.Size([2, 2, 4, 4]) = [B, H, S, S]
Head outputs: torch.Size([2, 2, 4, 4]) = [B, H, S, d_k]
✓ Each of 2 heads computed attention independently
Example: Attention weights from batch 0, head 0:
tensor([[4.7919e-01, 1.1970e-03, 5.1846e-01, 1.1548e-03],
[4.1243e-02, 8.7813e-01, 8.0629e-02, 1.2459e-07],
[1.7262e-06, 9.9997e-01, 2.7505e-08, 3.0176e-05],
[9.7811e-01, 4.3788e-06, 2.5453e-09, 2.1887e-02]])
Step 3: CONCATENATE HEADS
----------------------------------------------------------------------
Before concat: torch.Size([2, 2, 4, 4]) = [B, H, S, d_k]
After concat: torch.Size([2, 4, 8]) = [B, S, D]
✓ Merged 2 × 4 = 8 dimensions back together
Step 4: FINAL OUTPUT PROJECTION
----------------------------------------------------------------------
Final output: torch.Size([2, 4, 8]) = [B, S, D]
✓ One more learned mixing to combine head perspectives
======================================================================
✓ COMPLETE: Input [B,S,D] → Output [B,S,D]
======================================================================
Part 3: Visualizing Multiple Perspectives¶
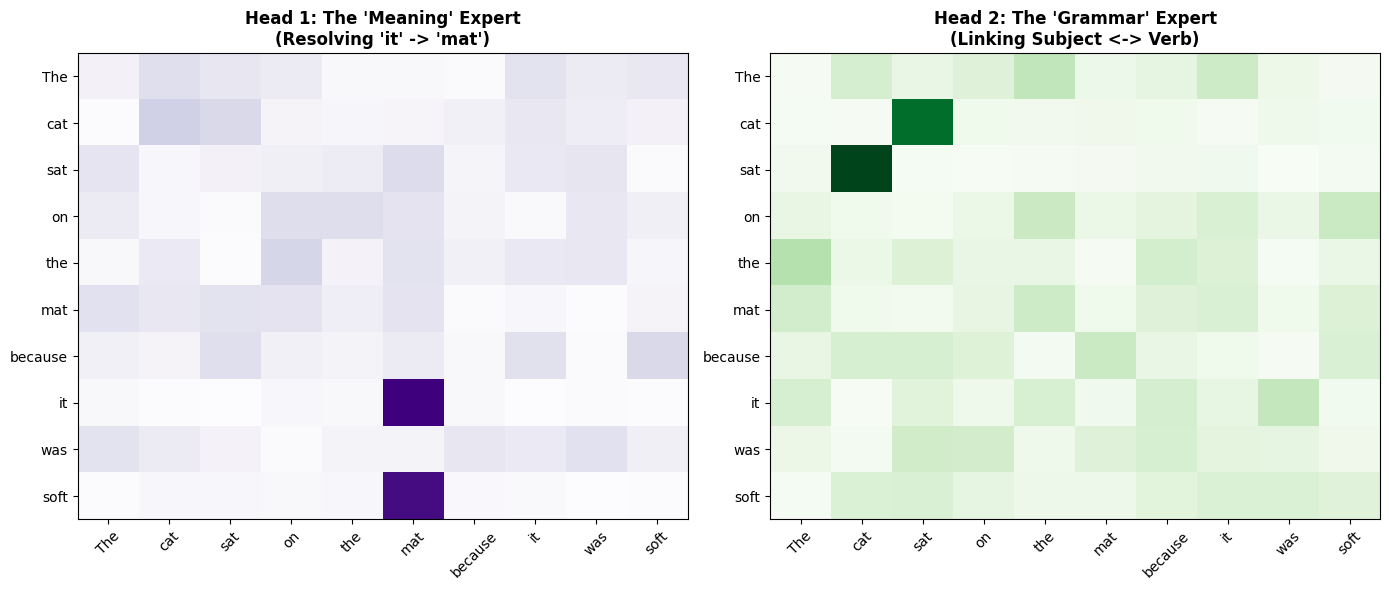
Let’s create a concrete example showing how two different heads learn different attention patterns on the same sentence.
Sentence: “The cat sat on the mat because it was soft.”
We’ll manually construct attention patterns to demonstrate what trained heads might learn:
Head 1 (Semantic): Focuses on meaning - connects “it” to “mat”
Head 2 (Syntactic): Focuses on grammar - connects “sat” to “cat” (subject-verb)
import numpy as np
import torch
import torch.nn.functional as F
tokens = ["The", "cat", "sat", "on", "the", "mat", "because", "it", "was", "soft"]
n_tokens = len(tokens)
print("Sentence:", " ".join(tokens))
print(f"Tokens: {n_tokens}")
print()
# Head 1: Semantic relationships (it -> mat, soft -> mat)
print("=" * 70)
print("HEAD 1: Semantic Expert")
print("=" * 70)
head1_logits = torch.zeros(n_tokens, n_tokens)
# "it" should attend to "mat" (physical reference)
head1_logits[tokens.index("it"), tokens.index("mat")] = 8.0
# "soft" should attend to "mat" (property)
head1_logits[tokens.index("soft"), tokens.index("mat")] = 6.0
# Everyone else attends mostly to themselves
for i in range(n_tokens):
if tokens[i] not in ["it", "soft"]:
head1_logits[i, i] = 5.0
head1_weights = F.softmax(head1_logits, dim=-1)
print("\nKey patterns in Head 1:")
for i, token in enumerate(tokens):
max_attn_idx = torch.argmax(head1_weights[i]).item()
max_attn_val = head1_weights[i, max_attn_idx].item()
if max_attn_val > 0.5:
print(f" '{token}' → '{tokens[max_attn_idx]}' ({max_attn_val:.2f})")
# Head 2: Syntactic relationships (verb -> subject)
print("\n" + "=" * 70)
print("HEAD 2: Syntactic Expert")
print("=" * 70)
head2_logits = torch.zeros(n_tokens, n_tokens)
# "sat" should attend to "cat" (subject of verb)
head2_logits[tokens.index("sat"), tokens.index("cat")] = 8.0
# "cat" should attend to "sat" (verb of subject)
head2_logits[tokens.index("cat"), tokens.index("sat")] = 6.0
# Everyone else attends mostly to themselves
for i in range(n_tokens):
if tokens[i] not in ["cat", "sat"]:
head2_logits[i, i] = 5.0
head2_weights = F.softmax(head2_logits, dim=-1)
print("\nKey patterns in Head 2:")
for i, token in enumerate(tokens):
max_attn_idx = torch.argmax(head2_weights[i]).item()
max_attn_val = head2_weights[i, max_attn_idx].item()
if max_attn_val > 0.5:
print(f" '{token}' → '{tokens[max_attn_idx]}' ({max_attn_val:.2f})")
print("\n" + "=" * 70)
print("✓ Different heads capture different linguistic relationships!")
print("=" * 70)Sentence: The cat sat on the mat because it was soft
Tokens: 10
======================================================================
HEAD 1: Semantic Expert
======================================================================
Key patterns in Head 1:
'The' → 'The' (0.94)
'cat' → 'cat' (0.94)
'sat' → 'sat' (0.94)
'on' → 'on' (0.94)
'the' → 'the' (0.94)
'mat' → 'mat' (0.94)
'because' → 'because' (0.94)
'it' → 'mat' (1.00)
'was' → 'was' (0.94)
'soft' → 'mat' (0.98)
======================================================================
HEAD 2: Syntactic Expert
======================================================================
Key patterns in Head 2:
'The' → 'The' (0.94)
'cat' → 'sat' (0.98)
'sat' → 'cat' (1.00)
'on' → 'on' (0.94)
'the' → 'the' (0.94)
'mat' → 'mat' (0.94)
'because' → 'because' (0.94)
'it' → 'it' (0.94)
'was' → 'was' (0.94)
'soft' → 'soft' (0.94)
======================================================================
✓ Different heads capture different linguistic relationships!
======================================================================
Now let’s visualize these patterns side-by-side:
Part 4: Implementation in PyTorch¶
In L03, we implemented single-head attention on batches [B, S, D]:
B = Batch size (multiple sequences processed in parallel)
S = Sequence length (number of tokens)
D = Embedding dimension (features per token)
Multi-head attention adds one more dimension: H (number of heads).
Our tensors now become [B, H, S, d_k] where:
H = Number of heads (e.g., 8)
d_k = Dimensions per head (d_k = D / H = 64)
The key challenge: How do we efficiently compute H attention mechanisms in parallel?
The answer: Clever tensor reshaping with view() and transpose(). Instead of looping over heads, PyTorch reshapes tensors so all heads run in parallel.
We’ll use heads and dims per head.
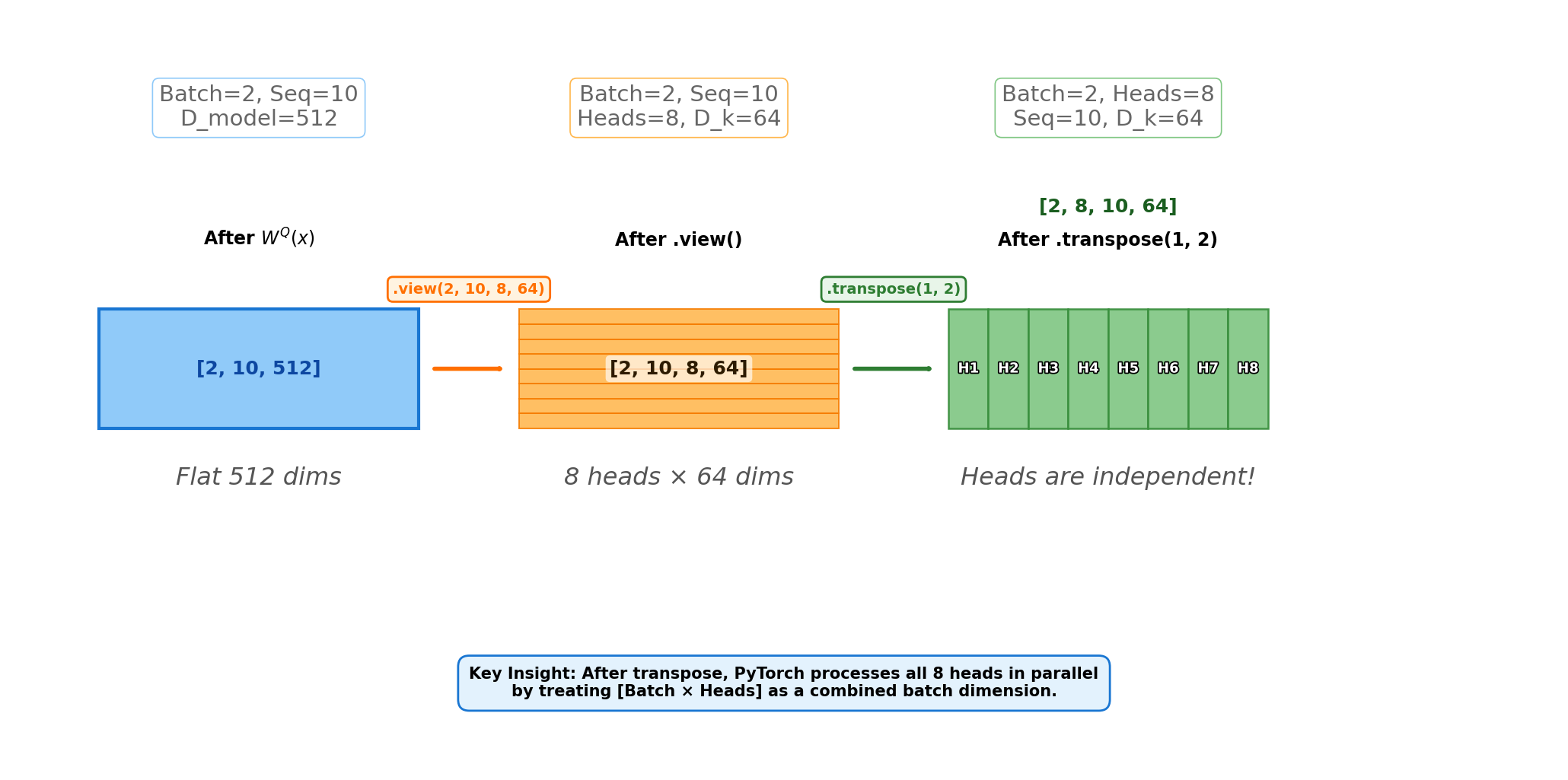
Project (Mix):
Apply to produce . Each projected feature can use all input dimensions.Split:
view(B, S, H, d_k)splits the last dimension into heads × per-head dims.Reorder:
transpose(1, 2)moves the heads dimension next to the batch dimension, so the tensor behaves like independent attention problems.
# Show the exact tensor operations in PyTorch (tiny shapes)
B, S, D = 2, 10, 512
H = 8
d_k = D // H
x_big = torch.randn(B, S, D)
Wq = torch.randn(D, D)
q = x_big @ Wq # [B,S,D]
q_view = q.view(B, S, H, d_k) # [B,S,H,d_k]
q_reordered = q_view.transpose(1, 2) # [B,H,S,d_k]
print("x_big:", x_big.shape)
print("q:", q.shape)
print("q_view:", q_view.shape)
print("q_reordered:", q_reordered.shape)
# The per-head slice is now easy:
print("One head slice:", q_reordered[:, 0].shape, "(= [B,S,d_k])")x_big: torch.Size([2, 10, 512])
q: torch.Size([2, 10, 512])
q_view: torch.Size([2, 10, 8, 64])
q_reordered: torch.Size([2, 8, 10, 64])
One head slice: torch.Size([2, 10, 64]) (= [B,S,d_k])
Now let’s visualize these tensor transformations:
Shape Transformation Table¶
Let’s trace the exact tensor shapes through a concrete example with batch=2, seq=10, d_model=512, heads=8:
| Operation | Shape | Description |
|---|---|---|
Input x | [2, 10, 512] | Raw input: 2 sequences, each with 10 tokens, 512-dim embeddings |
After W_q(x) | [2, 10, 512] | Linear projection (still flat) |
After .view(2, 10, 8, 64) | [2, 10, 8, 64] | Reshape: Split 512 dims into 8 heads × 64 dims each |
After .transpose(1, 2) | [2, 8, 10, 64] | Swap seq and heads: Now we have 8 “parallel attention mechanisms” |
| Attention computation | [2, 8, 10, 64] | Each head computes attention independently |
After .transpose(1, 2) | [2, 10, 8, 64] | Swap back: Prepare for concatenation |
After .contiguous().view(2, 10, 512) | [2, 10, 512] | Flatten: Merge 8 heads back into single 512-dim vector |
After W_o(x) | [2, 10, 512] | Final projection |
The key insight: dimensions 1 and 2 get swapped twice—once to parallelize the heads, and once to merge them back together.
# Why contiguous() matters (a runnable demo)
x_demo = torch.randn(2, 3, 4)
x_t = x_demo.transpose(1, 2) # changes strides, doesn't move data
print("x_t.is_contiguous():", x_t.is_contiguous())
try:
_ = x_t.view(2, 12) # may error if not contiguous
print("view() worked (unexpected in some layouts)")
except RuntimeError as e:
print("view() failed as expected:", e)
x_c = x_t.contiguous()
print("x_c.is_contiguous():", x_c.is_contiguous())
print("x_c.view(2, 12).shape:", x_c.view(2, 12).shape)x_t.is_contiguous(): False
view() failed as expected: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
x_c.is_contiguous(): True
x_c.view(2, 12).shape: torch.Size([2, 12])
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# We define 4 linear layers: Q, K, V projections and the final Output
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# 1. Project and Split
# We transform [Batch, Seq, Model] -> [Batch, Seq, Heads, d_k]
# Then we transpose to [Batch, Heads, Seq, d_k] for matrix multiplication
Q = self.W_q(q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(k).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(v).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 2. Scaled Dot-Product Attention (re-using logic from L03)
# Scores shape: [Batch, Heads, Seq, Seq]
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = torch.softmax(scores, dim=-1)
# Apply weights to Values
# Shape: [Batch, Heads, Seq, d_k]
attn_output = torch.matmul(attn_weights, V)
# 3. Concatenate
# Transpose back: [Batch, Seq, Heads, d_k]
# Flatten: [Batch, Seq, d_model]
attn_output = attn_output.transpose(1, 2)
attn_output = attn_output.contiguous()
attn_output = attn_output.view(batch_size, -1, self.d_model)
# 4. Final Projection (The "Mix")
return self.W_o(attn_output)# Demo: Test the MultiHeadAttention module
print("=" * 70)
print("TESTING MULTI-HEAD ATTENTION MODULE")
print("=" * 70)
torch.manual_seed(0)
d_model = 32
num_heads = 4
batch_size = 2
seq_len = 5
mha = MultiHeadAttention(d_model=d_model, num_heads=num_heads)
x_in = torch.randn(batch_size, seq_len, d_model)
print(f"\nConfiguration:")
print(f" d_model: {d_model}")
print(f" num_heads: {num_heads}")
print(f" d_k per head: {d_model // num_heads}")
print(f"\nInput shape: {x_in.shape} = [Batch, Seq, D_model]")
# Forward pass (self-attention: q=k=v=x)
y_out = mha(x_in, x_in, x_in)
print(f"Output shape: {y_out.shape} = [Batch, Seq, D_model]")
print(f"\n✓ Shape preserved: {x_in.shape} → {y_out.shape}")
# Show that output is different from input (attention mixed information)
diff = (y_out - x_in).abs().mean().item()
print(f"✓ Output differs from input (mean abs diff: {diff:.4f})")
print(" This means attention successfully mixed contextual information!")
# Show parameter count
total_params = sum(p.numel() for p in mha.parameters())
print(f"\n✓ Total parameters: {total_params:,}")
print(f" Breakdown:")
print(f" W_q: {d_model} × {d_model} = {d_model*d_model:,}")
print(f" W_k: {d_model} × {d_model} = {d_model*d_model:,}")
print(f" W_v: {d_model} × {d_model} = {d_model*d_model:,}")
print(f" W_o: {d_model} × {d_model} = {d_model*d_model:,}")
print(f" Total: {4*d_model*d_model:,}")
print("\n" + "=" * 70)======================================================================
TESTING MULTI-HEAD ATTENTION MODULE
======================================================================
Configuration:
d_model: 32
num_heads: 4
d_k per head: 8
Input shape: torch.Size([2, 5, 32]) = [Batch, Seq, D_model]
Output shape: torch.Size([2, 5, 32]) = [Batch, Seq, D_model]
✓ Shape preserved: torch.Size([2, 5, 32]) → torch.Size([2, 5, 32])
✓ Output differs from input (mean abs diff: 0.7951)
This means attention successfully mixed contextual information!
✓ Total parameters: 4,224
Breakdown:
W_q: 32 × 32 = 1,024
W_k: 32 × 32 = 1,024
W_v: 32 × 32 = 1,024
W_o: 32 × 32 = 1,024
Total: 4,096
======================================================================
# Verification: Loop-based vs Vectorized implementation produce identical results
def mha_forward_loop(mha_module, x, mask=None):
"""
A loop-based implementation that's easier to understand.
This should produce IDENTICAL results to the vectorized version.
"""
B, S, D = x.shape
H = mha_module.num_heads
d_k = mha_module.d_k
# Same projections as the module
Q = mha_module.W_q(x) # [B,S,D]
K = mha_module.W_k(x)
V = mha_module.W_v(x)
# Split into heads (without transpose yet, to make slicing intuitive)
Qs = Q.view(B, S, H, d_k)
Ks = K.view(B, S, H, d_k)
Vs = V.view(B, S, H, d_k)
heads = []
for h in range(H):
qh = Qs[:, :, h, :] # [B,S,d_k]
kh = Ks[:, :, h, :]
vh = Vs[:, :, h, :]
scores = qh @ kh.transpose(-2, -1) / math.sqrt(d_k) # [B,S,S]
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn = torch.softmax(scores, dim=-1)
out = attn @ vh # [B,S,d_k]
heads.append(out)
concat = torch.cat(heads, dim=-1) # [B,S,D]
return mha_module.W_o(concat)
print("=" * 70)
print("VERIFICATION: Vectorized vs Loop-Based Implementation")
print("=" * 70)
torch.manual_seed(123)
mha = MultiHeadAttention(d_model=32, num_heads=4)
x_in = torch.randn(2, 6, 32)
print(f"\nInput: {x_in.shape}")
y_vec = mha(x_in, x_in, x_in)
y_loop = mha_forward_loop(mha, x_in)
print(f"Vectorized output: {y_vec.shape}")
print(f"Loop-based output: {y_loop.shape}")
max_diff = (y_vec - y_loop).abs().max().item()
mean_diff = (y_vec - y_loop).abs().mean().item()
print(f"\nDifference between implementations:")
print(f" Max absolute diff: {max_diff:.10f}")
print(f" Mean absolute diff: {mean_diff:.10f}")
print(f" Results match: {torch.allclose(y_vec, y_loop, atol=1e-6)}")
print("\n✓ Both implementations produce identical results!")
print(" The vectorized version is just faster on GPUs")
print("=" * 70)======================================================================
VERIFICATION: Vectorized vs Loop-Based Implementation
======================================================================
Input: torch.Size([2, 6, 32])
Vectorized output: torch.Size([2, 6, 32])
Loop-based output: torch.Size([2, 6, 32])
Difference between implementations:
Max absolute diff: 0.0000000000
Mean absolute diff: 0.0000000000
Results match: True
✓ Both implementations produce identical results!
The vectorized version is just faster on GPUs
======================================================================
# Demo: Causal masking (for GPT-style models)
print("=" * 70)
print("CAUSAL MASKING EXAMPLE")
print("=" * 70)
B, S, D = 2, 6, 32
mha = MultiHeadAttention(d_model=D, num_heads=4)
x_in = torch.randn(B, S, D)
# causal mask: [S,S] lower triangular -> broadcastable to [B,1,S,S]
causal = torch.tril(torch.ones(S, S)).unsqueeze(0).unsqueeze(1)
print(f"\nCausal mask shape: {causal.shape} (will broadcast to [B, H, S, S])")
print(f"Causal mask (first 4x4 for visualization):")
print(causal[0, 0, :4, :4].int())
print(" 1 = can attend, 0 = cannot attend (future tokens masked)")
y_masked = mha(x_in, x_in, x_in, mask=causal)
y_unmasked = mha(x_in, x_in, x_in, mask=None)
print(f"\nMasked output: {y_masked.shape}")
print(f"Unmasked output: {y_unmasked.shape}")
diff = (y_masked - y_unmasked).abs().mean().item()
print(f"\nMean absolute difference: {diff:.4f}")
print("✓ Masking changes the output - tokens can't peek at the future!")
print("\nNote: Causal masking is used in GPT models to prevent")
print(" tokens from attending to future positions during training.")
print("=" * 70)======================================================================
CAUSAL MASKING EXAMPLE
======================================================================
Causal mask shape: torch.Size([1, 1, 6, 6]) (will broadcast to [B, H, S, S])
Causal mask (first 4x4 for visualization):
tensor([[1, 0, 0, 0],
[1, 1, 0, 0],
[1, 1, 1, 0],
[1, 1, 1, 1]], dtype=torch.int32)
1 = can attend, 0 = cannot attend (future tokens masked)
Masked output: torch.Size([2, 6, 32])
Unmasked output: torch.Size([2, 6, 32])
Mean absolute difference: 0.0999
✓ Masking changes the output - tokens can't peek at the future!
Note: Causal masking is used in GPT models to prevent
tokens from attending to future positions during training.
======================================================================
Summary¶
Multiple Heads: We split our embedding into smaller chunks to allow the model to focus on different linguistic features simultaneously.
Projection: We use learned linear layers () to project the input into these specialized subspaces.
Parallelism: We use tensor reshaping (
viewandtranspose) to compute attention for all heads at once, rather than looping through them.
Next Up: L05 – Layer Norm & Residuals. We have built the engine (Attention), but if we stack 100 of these layers on top of each other, the gradients will vanish or explode. In L05, we will add the “plumbing” (Normalization and Skip Connections) that allows Deep Learning to actually get deep.