How to stop gradients from vanishing and signals from exploding
In L04, we built the Multi-Head Attention engine. But there’s a problem: in a deep LLM, we stack these attention layers dozens of times. As the data flows through these transformations, the numbers can drift—they might become tiny (vanishing gradients) or massive (exploding activations).
If the numbers get weird, the model stops learning. To fix this, Transformers use a critical pattern called “Add & Norm”—a combination of two techniques that work together:
Residual (Skip) Connections (“Add”): Provide a direct path for gradients to flow backward
Layer Normalization (“Norm”): Keep activations in a healthy range
Think of it like this: Multi-Head Attention does the thinking, while Add & Norm does the housekeeping to keep the network trainable.
By the end of this post, you’ll understand:
The intuition behind Add & Norm as a unit
Why Residual Connections allow for incredibly deep models (100+ layers)
How to implement LayerNorm from scratch
How to wrap L04’s MultiHeadAttention in a complete Transformer block
Part 1: Residual Connections (The Skip)¶
In a standard network, data flows like this:
In a Transformer, we do this:
We literally add the input back to the output.
Why?
Imagine you are trying to describe a complex concept. If you only give the “transformed” explanation, you might lose the original context. By adding the input back, we provide a “highway” for the original signal to travel through.
Visualizing Gradient Flow: With vs. Without Residuals¶
Let’s see the dramatic difference residual connections make in a deep network:
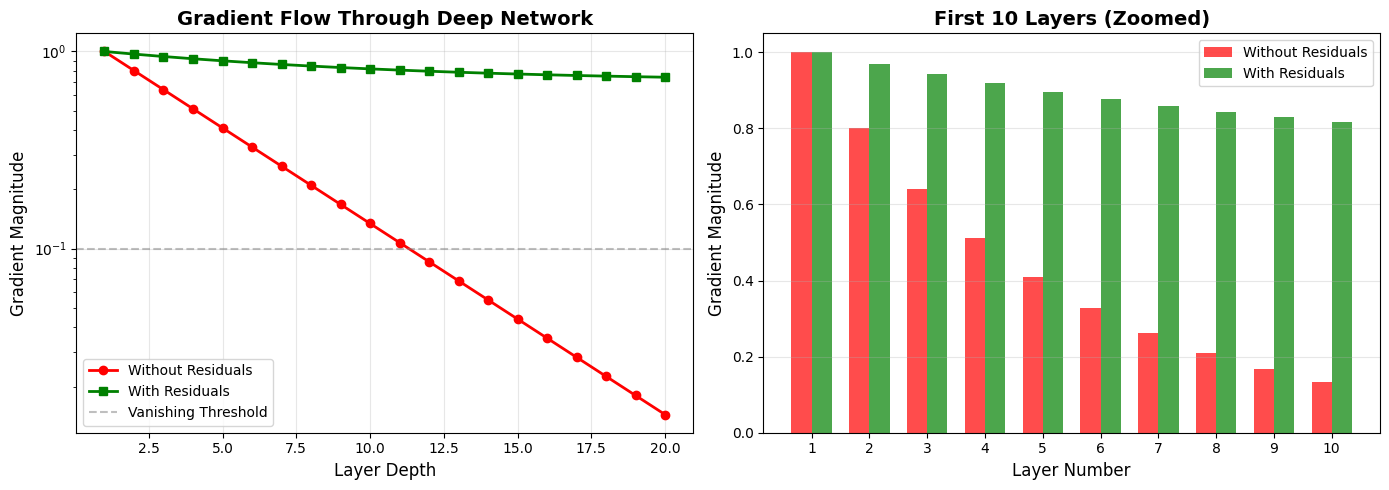
Key observations:
Without residuals (red): Gradients decay exponentially, reaching near-zero by layer 10-15
With residuals (green): Gradients remain strong even in deep layers
This is why we can train 100+ layer transformers successfully!
Part 2: Layer Normalization (The Leveler)¶
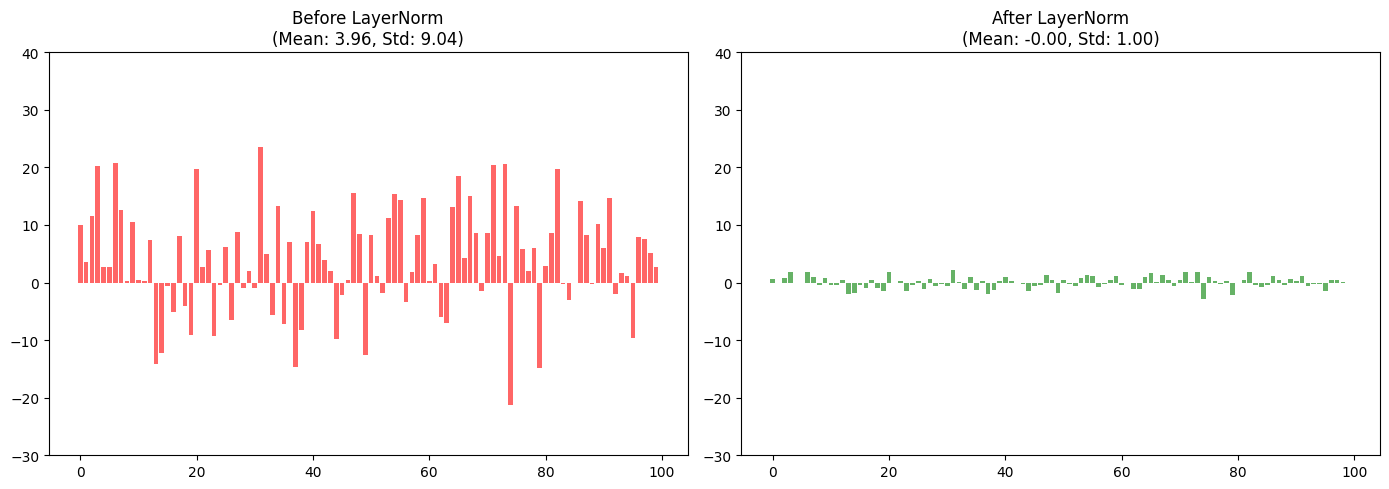
LayerNorm ensures that for every token, the mean of its features is 0 and the standard deviation is 1. This prevents any single feature or layer from dominating the calculation.
Unlike BatchNorm (common in CNNs), LayerNorm calculates statistics across the features of a single token. This makes it perfect for sequences of varying lengths.
LayerNorm vs. BatchNorm: What’s the Difference?¶
Both normalization techniques aim to stabilize training, but they compute statistics over different dimensions:
| Aspect | BatchNorm | LayerNorm |
|---|---|---|
| Normalizes across | Batch dimension (across examples) | Feature dimension (within each example) |
| Input shape | [Batch, Features] or [Batch, Channels, Height, Width] | [Batch, Seq_Len, Features] |
| Statistics computed | Mean/Std for each feature across all examples in batch | Mean/Std for each example across all features |
| Dependencies | Requires large batches to get good statistics | Works with batch size = 1 |
| Typical use | CNNs (image tasks) | Transformers, RNNs (sequence tasks) |
Why LayerNorm for Transformers?
Variable sequence lengths: Different sentences have different lengths. BatchNorm would struggle with varying dimensions.
Batch independence: Each example can be normalized independently, making it work even with tiny batches (e.g., batch_size=1 during inference).
Recurrent/sequential nature: In sequences, we care about the distribution of features within each token, not across different tokens in a batch.
Visual Comparison:
BatchNorm (shape [4, 512]): LayerNorm (shape [4, 512]):
┌─────────────────┐ ┌─────────────────┐
│ Example 1 │ │ Example 1 │ ← Normalize these 512 values
│ Example 2 │ ↑ │ Example 2 │ ← Normalize these 512 values
│ Example 3 │ │ Normalize │ Example 3 │ ← Normalize these 512 values
│ Example 4 │ │ each column │ Example 4 │ ← Normalize these 512 values
└─────────────────┘ ↓ └─────────────────┘The Formula
For a vector (the features of a single token):
Where:
= mean of the features:
= variance of the features:
= small constant (e.g., 10-6) to prevent division by zero
= learnable scale parameter (initialized to 1)
= learnable shift parameter (initialized to 0)
Steps:
Calculate mean and variance across all features
Normalize: subtract mean and divide by standard deviation
Scale and shift: and let the model adjust the range if needed for learning
Part 3: Visualizing the “Add & Norm”¶
First, let’s see the complete Add & Norm pipeline in action:
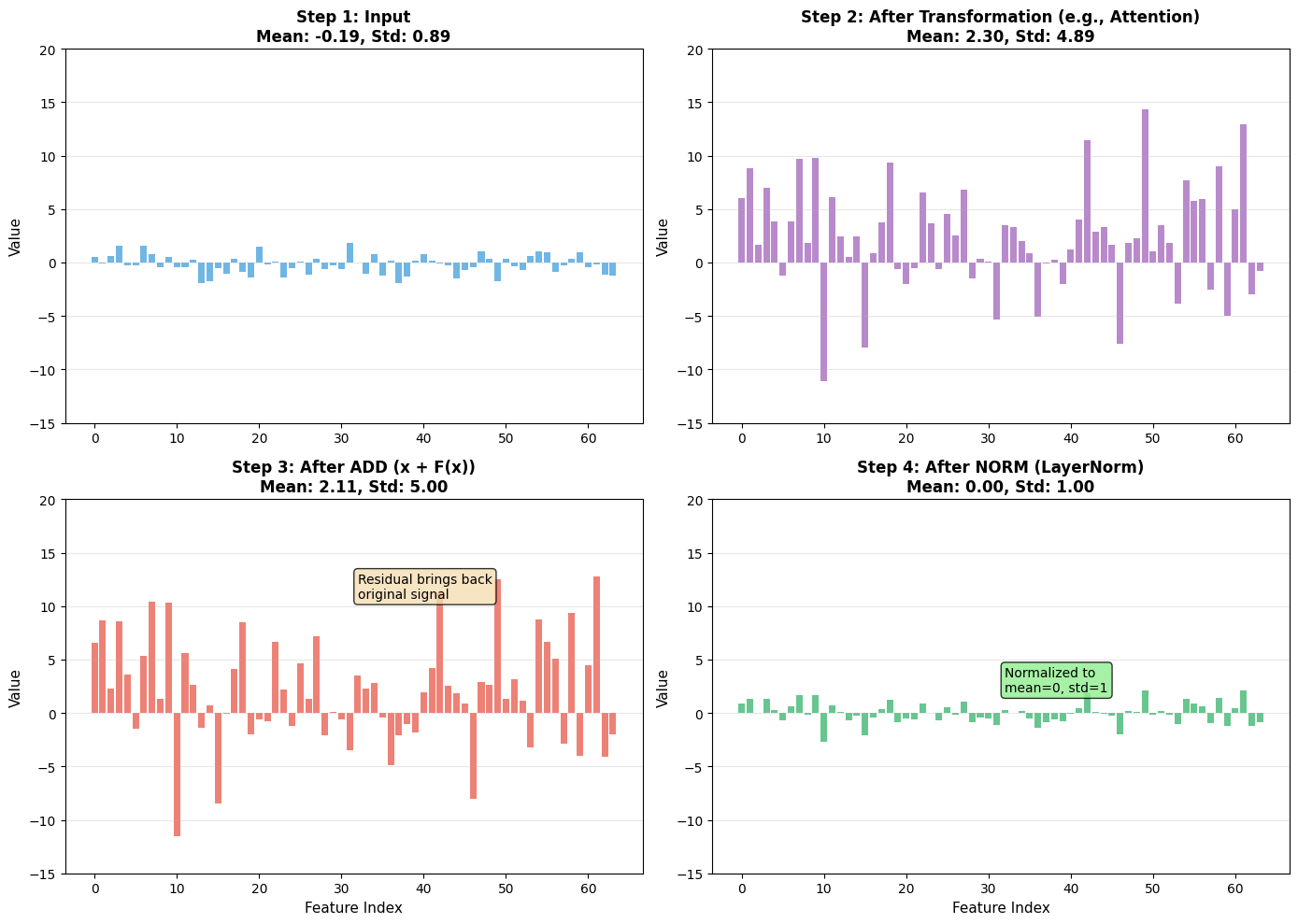
Key Observations:
Step 3 (ADD): The residual connection preserves the original signal, even if the transformation changed the statistics
Step 4 (NORM): LayerNorm brings everything back to a standard range (mean≈0, std≈1), preventing runaway values in deep networks
Together: ADD ensures gradient flow, NORM ensures numerical stability
Now let’s zoom in on LayerNorm specifically:
Part 4: Building LayerNorm from Scratch¶
While PyTorch has nn.LayerNorm, building it yourself helps you understand exactly where those learnable parameters () live.
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-6):
super().__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
# x shape: [batch, seq_len, d_model]
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
# Normalize
x_norm = (x - mean) / (std + self.eps)
# Scale and Shift
return self.gamma * x_norm + self.beta
Let’s test it:
# Test LayerNorm implementation
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-6):
super().__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
# x shape: [batch, seq_len, d_model]
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
# Normalize
x_norm = (x - mean) / (std + self.eps)
# Scale and Shift
return self.gamma * x_norm + self.beta
# Create test data
torch.manual_seed(0)
batch, seq_len, d_model = 2, 4, 8
x_test = torch.randn(batch, seq_len, d_model) * 10 + 5 # Wild distribution
# Apply LayerNorm
ln = LayerNorm(d_model)
x_normed = ln(x_test)
print("Before LayerNorm:")
print(f" Mean: {x_test.mean(-1)[0, 0]:.3f}")
print(f" Std: {x_test.std(-1)[0, 0]:.3f}")
print()
print("After LayerNorm:")
print(f" Mean: {x_normed.mean(-1)[0, 0]:.3f}")
print(f" Std: {x_normed.std(-1)[0, 0]:.3f}")
print()
print("✓ LayerNorm normalized to mean≈0, std≈1")Before LayerNorm:
Mean: 0.184
Std: 9.830
After LayerNorm:
Mean: -0.000
Std: 1.000
✓ LayerNorm normalized to mean≈0, std≈1
Part 4b: Putting It Together - The Complete Transformer Block¶
Now let’s combine Add & Norm with the MultiHeadAttention from L04 to build a complete Transformer block:
# Import MultiHeadAttention from L04 (we'll reimplement it here for completeness)
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
batch_size = q.size(0)
# 1. Project and split into heads
Q = self.W_q(q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(k).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(v).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 2. Scaled dot-product attention
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = torch.softmax(scores, dim=-1)
attn_output = torch.matmul(attn_weights, V)
# 3. Concatenate heads
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 4. Final projection
return self.W_o(attn_output)
class FeedForward(nn.Module):
"""Simple 2-layer feed-forward network (we'll cover this in L07)"""
def __init__(self, d_model, d_ff=2048):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear2(torch.relu(self.linear1(x)))
class TransformerBlock(nn.Module):
"""
A complete Transformer block with Add & Norm (Pre-Norm style).
This is what GPT and most modern LLMs use.
"""
def __init__(self, d_model, num_heads, d_ff=2048):
super().__init__()
self.attention = MultiHeadAttention(d_model, num_heads)
self.norm1 = LayerNorm(d_model)
self.norm2 = LayerNorm(d_model)
self.ffn = FeedForward(d_model, d_ff)
def forward(self, x, mask=None):
# Pre-Norm: Attention block
# 1. Normalize
x_norm = self.norm1(x)
# 2. Apply attention
attn_out = self.attention(x_norm, x_norm, x_norm, mask)
# 3. Add residual
x = x + attn_out
# Pre-Norm: Feed-forward block
# 1. Normalize
x_norm = self.norm2(x)
# 2. Apply FFN
ffn_out = self.ffn(x_norm)
# 3. Add residual
x = x + ffn_out
return x
print("=" * 70)
print("COMPLETE TRANSFORMER BLOCK")
print("=" * 70)
# Create a transformer block
torch.manual_seed(0)
d_model = 512
num_heads = 8
batch, seq_len = 2, 10
block = TransformerBlock(d_model, num_heads)
x_in = torch.randn(batch, seq_len, d_model)
print(f"\nInput shape: {x_in.shape}")
# Forward pass
x_out = block(x_in)
print(f"Output shape: {x_out.shape}")
print()
print("✓ Shape preserved: [Batch, Seq, D_model]")
print("✓ This is the basic building block of GPT!")
print()
# Show that output is different (attention mixed information)
diff = (x_out - x_in).abs().mean().item()
print(f"Mean absolute difference: {diff:.4f}")
print("✓ Output differs from input (attention + FFN transformed the data)")
print()
# Show parameter count
total_params = sum(p.numel() for p in block.parameters())
print(f"Total parameters in one block: {total_params:,}")
print()
print("Note: A GPT-3 scale model stacks ~96 of these blocks!")
print("=" * 70)======================================================================
COMPLETE TRANSFORMER BLOCK
======================================================================
Input shape: torch.Size([2, 10, 512])
Output shape: torch.Size([2, 10, 512])
✓ Shape preserved: [Batch, Seq, D_model]
✓ This is the basic building block of GPT!
Mean absolute difference: 0.2057
✓ Output differs from input (attention + FFN transformed the data)
Total parameters in one block: 3,152,384
Note: A GPT-3 scale model stacks ~96 of these blocks!
======================================================================
Key Observations:
Pre-Norm style: Normalize → Transform → Add residual
Two sub-blocks: Attention + FFN, each with its own Add & Norm
Shape preservation: Input [B, S, D] → Output [B, S, D]
Residual connections: Ensure gradients can flow backward through all 96+ layers
Part 5: Pre-Norm vs. Post-Norm - Where to Place LayerNorm?¶
There are two ways to combine residuals and normalization in a Transformer block, and the choice has significant training implications:
Post-Norm (Original Transformer)¶
x = LayerNorm(x + Attention(x))
x = LayerNorm(x + FeedForward(x))How it works:
Apply the transformation (Attention or FFN)
Add the residual
Normalize the result
Characteristics:
Used in the original “Attention is All You Need” paper
Gradients can still be large early in training
Often requires learning rate warmup and careful tuning
Pre-Norm (Modern Standard)¶
x = x + Attention(LayerNorm(x))
x = x + FeedForward(LayerNorm(x))How it works:
Normalize the input first
Apply the transformation
Add the residual
Characteristics:
Used by GPT-2, GPT-3, and most modern LLMs
More stable gradients throughout training
Easier to train (less sensitive to hyperparameters)
The residual path stays “clean” (unnormalized)
Visual Comparison¶
Why Pre-Norm Won:
Empirically, Pre-Norm is more stable and easier to optimize
The gradient flowing through the residual connection doesn’t pass through LayerNorm
Works better for very deep networks (100+ layers)
Summary¶
Residual Connections create a “high-speed rail” for gradients, preventing the vanishing gradient problem through the “+1” term in the derivative.
LayerNorm re-centers activations at every step, keeping the optimization process stable by normalizing across features (not batches).
Pre-Norm vs. Post-Norm: Most modern LLMs use Pre-Norm (normalize before the sub-layer) because it’s more stable to train and less sensitive to hyperparameters.
The Complete Block: We combined L04’s MultiHeadAttention with Add & Norm to build a
TransformerBlock—the fundamental building block of GPT.
What We’ve Built So Far:
L01: Text → Tokens
L02: Tokens → Vectors
L03: Single-Head Attention
L04: Multi-Head Attention
L05: Add & Norm (making it stackable)
Next Up: L06 – The Causal Mask. When training a language model to predict the next word, how do we stop it from “cheating” by looking at future tokens? We’ll build the triangular mask that hides the future.