Transforming a base LLM into a helpful Chat Assistant
We have reached the finish line. In L09 Inference and Sampling, we saw that our model can complete text. However, if you ask a “Base” model: “What is the capital of France?”, it might respond with: “...and what is the capital of Germany?”
This final post concludes the journey by explaining how we transition from a model that simply “predicts the next word” to a model that can actually follow instructions and act as a helpful assistant.
Why? Because it thinks it’s looking at a geography quiz, not a conversation. It is a completion engine, not an assistant. To fix this, we need Fine-tuning.
By the end of this post, you’ll understand:
The difference between Pre-training and Fine-tuning.
SFT (Supervised Fine-Tuning): Teaching the model to follow instructions.
RLHF (Reinforcement Learning from Human Feedback): Aligning the model with human values.
Part 1: The Two Stages of Training¶
Building a Chatbot is a two-step process:
Pre-training (The Library): The model reads the whole internet. It learns grammar, facts, and reasoning. This creates the Base Model.
Fine-tuning (The Training): We show the model specific examples of “Question -> Answer” pairs. This creates the Chat/Instruct Model.
Part 2: Supervised Fine-Tuning (SFT) - Teaching by Example¶
During SFT, we use a smaller, high-quality dataset of dialogues (typically 10K-100K examples, vs. billions for pre-training). We format them using special tokens so the model knows who is talking.
Chat Templates - The Conversation Format¶
Modern chat models use structured templates to distinguish between different speakers:
Example Chat Template (ChatML format):
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
What is 2+2?<|im_end|>
<|im_start|>assistant
2+2 is 4.<|im_end|>Breaking it down:
<|im_start|>and<|im_end|>mark message boundariessystem: Sets the assistant’s behavior/personalityuser: The human’s messageassistant: The model’s response
Alternative formats used by different models:
# Llama 2 format
"<s>[INST] <<SYS>>\nYou are helpful.\n<</SYS>>\n\nWhat is 2+2? [/INST] 2+2 is 4.</s>"
# Alpaca format
"### Instruction:\nWhat is 2+2?\n\n### Response:\n2+2 is 4."
# ChatML (GPT-4, others)
"<|im_start|>user\nWhat is 2+2?<|im_end|>\n<|im_start|>assistant\n2+2 is 4.<|im_end|>"SFT Training Code¶
The key difference from pre-training: we only compute loss on the assistant’s tokens, not the user’s message:
def prepare_sft_batch(conversations, tokenizer):
"""
Convert chat conversations into training tensors with appropriate masking.
Args:
conversations: List of chat dialogues
tokenizer: The tokenizer with chat template support
Returns:
input_ids: Token IDs [batch, seq_len]
labels: Target IDs [batch, seq_len], with -100 for ignored positions
"""
input_ids = []
labels = []
for conv in conversations:
# Format: [{"role": "user", "content": "..."}, {"role": "assistant", "content": "..."}]
full_text = tokenizer.apply_chat_template(conv, tokenize=False)
tokens = tokenizer.encode(full_text)
# Create labels: -100 for user tokens (ignored in loss), actual tokens for assistant
label = []
current_role = None
for msg in conv:
msg_tokens = tokenizer.encode(msg['content'])
if msg['role'] == 'assistant':
# Compute loss on assistant responses
label.extend(msg_tokens)
else:
# Ignore loss on user messages and system prompts
label.extend([-100] * len(msg_tokens))
input_ids.append(tokens)
labels.append(label)
return torch.tensor(input_ids), torch.tensor(labels)
# Training loop
model.train()
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5) # Lower LR than pre-training
for epoch in range(num_epochs): # Typically 1-3 epochs for SFT
for batch in sft_dataloader:
input_ids, labels = prepare_sft_batch(batch, tokenizer)
# Forward pass
logits = model(input_ids) # [batch, seq, vocab_size]
# Compute loss only on non-ignored tokens (labels != -100)
loss = F.cross_entropy(
logits.view(-1, vocab_size),
labels.view(-1),
ignore_index=-100 # This makes the model ignore user tokens
)
# Backward pass
loss.backward()
optimizer.step()
optimizer.zero_grad()Key differences from pre-training:
Smaller learning rate (2e-5 vs 6e-4): The model already knows language, we’re just teaching it conversation
Fewer epochs (1-3 vs 1 epoch over billions of tokens): Prevents overfitting on small dataset
Masked loss (
ignore_index=-100): Only learn from assistant responsesCurated data: High-quality human demonstrations instead of raw web text
Part 3: RLHF - Learning from Human Taste¶
Sometimes, “correct” isn’t enough. We want the model to be polite, safe, and helpful. A model might give 10 different factually correct answers, but only one that’s truly helpful.
RLHF (Reinforcement Learning from Human Feedback) is how we teach models human preferences. It’s a 3-step process:
Step 1: Train a Reward Model (RM)¶
First, we need to teach a model what “good” and “bad” responses look like from a human perspective.
Data Collection:
Prompt: "Explain quantum computing"
Response A: "Quantum computing uses qubits which can be 0 and 1 at the same time..."
Response B: "Quantum computing? That's like really fast computers or whatever lol idk"
Human labels: A > B (A is better than B)We collect thousands of such pairwise comparisons from human labelers.
Training the Reward Model:
class RewardModel(nn.Module):
def __init__(self, base_model):
super().__init__()
self.base = base_model # Use the same GPT architecture
self.reward_head = nn.Linear(d_model, 1) # Output single scalar reward
def forward(self, input_ids):
# Get final hidden state
hidden = self.base(input_ids)[:, -1, :] # [batch, d_model]
# Predict reward score
reward = self.reward_head(hidden) # [batch, 1]
return reward
# Training objective: Bradley-Terry model
def reward_loss(reward_a, reward_b):
"""
reward_a: Reward for preferred response A
reward_b: Reward for dis-preferred response B
"""
# We want: P(A > B) = sigmoid(reward_a - reward_b) ≈ 1
return -torch.log(torch.sigmoid(reward_a - reward_b)).mean()
# Training loop
for batch in comparison_data:
prompt, response_a, response_b, preference = batch # preference: A > B
# Get rewards for both responses
reward_a = reward_model(prompt + response_a)
reward_b = reward_model(prompt + response_b)
loss = reward_loss(reward_a, reward_b)
loss.backward()
optimizer.step()What the RM learns:
High scores for helpful, harmless, honest responses
Low scores for incorrect, rude, or harmful content
Captures subtle human preferences (tone, detail level, safety)
Step 2: Optimize with PPO (Proximal Policy Optimization)¶
Now we use the reward model to improve the LLM. But we can’t just use supervised learning—we need reinforcement learning.
Why not just supervised learning on “good” responses?
We’d need humans to write perfect responses for every possible prompt
The model might memorize rather than generalize
We want the model to explore and find even better responses than humans wrote
PPO Training Loop:
# Start from SFT model
policy_model = load_sft_model() # The model we're improving
reference_model = copy.deepcopy(policy_model) # Frozen copy
reward_model = load_trained_reward_model() # From Step 1
for prompt in training_prompts:
# 1. Generate response with current policy
response = policy_model.generate(prompt)
# 2. Calculate reward
reward = reward_model(prompt + response)
# 3. KL penalty: don't drift too far from SFT model
log_prob_policy = policy_model.log_prob(response | prompt)
log_prob_reference = reference_model.log_prob(response | prompt)
kl_penalty = (log_prob_policy - log_prob_reference)
# 4. Combined objective
objective = reward - beta * kl_penalty # beta ≈ 0.01-0.1
# 5. Update policy to maximize objective
objective.backward()
optimizer.step()Key components:
Reward: The reward model’s score for this response
KL Penalty: Prevents the model from “gaming” the reward model by drifting into nonsense
Beta: Controls the tradeoff (higher beta = stay closer to SFT model)
Why PPO specifically?
Proximal: Only makes small updates per step (stable training)
Policy Optimization: Treats text generation as a sequential decision problem
Clipping: Prevents destructively large updates that could break the model
Step 3: Iterate¶
The process is often repeated:
Use the improved model to generate new responses
Collect more human feedback
Retrain the reward model
Run more PPO training
RLHF vs. Just Supervised Fine-Tuning:
| Aspect | SFT Only | SFT + RLHF |
|---|---|---|
| Data needed | Demonstrations (prompt + response) | Comparisons (which response is better) |
| What it learns | Mimic specific responses | General preferences |
| Quality ceiling | Limited by training data quality | Can exceed training data |
| Safety | Harder to ensure | Easier to align with human values |
| Cost | Cheaper (need fewer examples) | More expensive (reward model + PPO) |
Example improvement from RLHF:
SFT model: “To rob a bank, you would need... [detailed illegal instructions]”
After RLHF: “I can’t help with that. Bank robbery is illegal and harmful. If you’re interested in security systems for educational purposes, I can discuss that instead.”
Part 4: Base Model vs. Chat Model - Concrete Examples¶
Let’s see exactly how behavior changes through fine-tuning with real examples:
Example 1: Direct Question¶
Prompt: “What is the capital of France?”
Base Model (Pre-training only):
What is the capital of France? What is the capital of Germany? What is the
capital of Italy? These are common questions on geography exams. Students
should memorize the major capitals...It continues the pattern, treating it as part of a list or quiz.
Chat Model (After SFT + RLHF):
The capital of France is Paris. It's the largest city in France and has been
the country's capital since the 12th century.It directly answers the question.
Example 2: Instruction Following¶
Prompt: “Write a haiku about programming.”
Base Model:
Write a haiku about programming. Here are some examples of haikus:
- The old pond, a frog jumps in, splash!
- In the cicada's cry, no sign can tell how soon it must dieIt treats it as the start of a document about haikus, not as a command.
Chat Model:
Code flows through my mind,
Debugging until sunrise,
Coffee fuels the loop.It follows the instruction and generates a haiku.
Example 3: Ambiguous Context¶
Prompt: “Python”
Base Model:
Python is a genus of constricting snakes in the Pythonidae family. They are
found in Africa, Asia, and Australia. The largest species is the reticulated
python...Continues with information about snake pythons (most common usage in web text).
Chat Model:
Are you asking about the Python programming language, or the snake? I'd be
happy to help with either!
If you're interested in Python programming, it's a popular high-level language
known for its readability and versatility...Recognizes ambiguity and asks for clarification.
Visualizing the Probability Shift¶
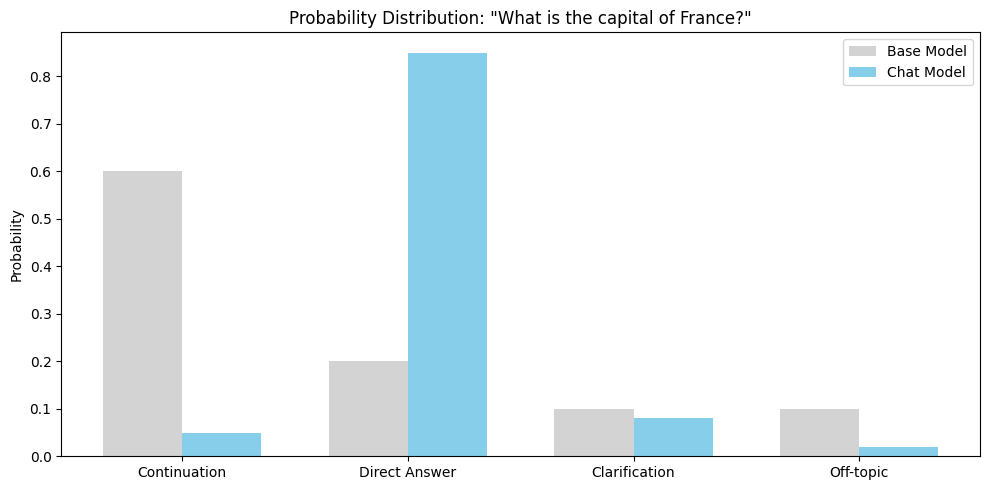
Key behavioral shifts:
Task completion over document continuation
User-centric responses over factual dumps
Safety guardrails against harmful requests
Conversational memory (in multi-turn chats)
Summary: The Complete Journey¶
Over these 10 lessons, we have traveled from raw text to a functional, instruction-following AI:
L01-L02: The Foundation
Tokenization: Converting text to numbers
Embeddings: Giving those numbers meaning
Positional Encoding: Teaching models about order
L03-L06: The Core Architecture
Attention: How words look at each other
Multi-Head Attention: Multiple perspectives simultaneously
Normalization & Residuals: Making deep networks trainable
Causal Masking: Preventing cheating during training
L07-L09: Building and Using the Model
Assembling the GPT: Stacking all components
Training: Teaching the model language through next-token prediction
Inference: Controlling creativity with temperature and sampling
L10: From Completion to Conversation
SFT: Teaching the model to follow instructions
RLHF: Aligning with human preferences and values
Chat Templates: Structuring conversations
You now have the complete blueprints to understand, build, and fine-tune transformer-based language models from scratch.
What’s Next? - Expanding Your LLM Knowledge¶
You’ve built the foundation. Here are paths forward:
1. Practical Implementation Projects¶
Train on TinyShakespeare: Use the code from L07 to train a small GPT on Shakespeare’s works
Fine-tune for a specific task: Create a coding assistant, creative writer, or domain expert
Build a chatbot: Implement the chat templates from this lesson and deploy a simple assistant
2. Performance Optimization¶
Quantization: Reduce model size from FP32 to INT8 (4-8× smaller, faster)
KV Caching: Speed up inference by caching key-value pairs from previous tokens
Flash Attention: Use optimized attention implementations for 2-4× speedup
Mixed Precision Training: Train with FP16/BF16 to reduce memory and speed up training
3. Advanced Architecture Variants¶
Rotary Positional Embeddings (RoPE): Modern alternative to sinusoidal encoding (used in Llama)
Grouped Query Attention (GQA): Reduce KV cache memory (used in Llama 2)
Sparse Attention: Handle longer contexts efficiently
Mixture of Experts (MoE): Scale up model capacity without proportional compute cost
4. Deployment & Production¶
Model Serving: Deploy with FastAPI, TorchServe, or vLLM
Batch Processing: Optimize throughput with dynamic batching
Monitoring: Track latency, throughput, and quality metrics
Safety Layers: Add content filtering and abuse detection
5. Retrieval-Augmented Generation (RAG)¶
Vector Databases: Store and retrieve relevant documents
Hybrid Search: Combine semantic and keyword search
Citation & Grounding: Make models cite sources and reduce hallucinations
6. Research Frontiers¶
Constitutional AI: Safer alignment without human feedback
Chain-of-Thought: Teaching models to show their reasoning
Multi-modal Models: Extend to images, video, audio
Efficient Fine-tuning: LoRA, QLoRA, and parameter-efficient methods
Final Thoughts¶
The transformer architecture you’ve learned is one of the most important breakthroughs in modern AI. The same fundamental principles apply whether you’re building:
A chatbot with 7B parameters
A code completion engine
A translation system
Or GPT-4 with hundreds of billions of parameters
The difference is scale, compute, and data—but the architecture is the same.
Thank you for following this “From Scratch” series. You now understand the technology powering the AI revolution. Go build something amazing!